hyPACK-2013 Mode 1 : Mixed Mode of Prog. Using MPI & Intel TBB
|
Mixed Mode of Programming Using MPI & TBB |
|
Examples using a mixed(hybrid) mode-programming model such as MPI-TBB have been discussed.
By utilizing the mixed(hybrid) mode-programming model (MPI-OpenMP, MPI-TBB) ,we should be able to take
advantage of the benefits of both models. The majority of mixed mode applications involve a hierarchical model,
MPI parallelisation occurring at the top level, and OpenMP parallelisation occurring below .
|
Click here ...... to know more about MPI-TBB codes
|
The mixed programming model which is combination of Message Passing Model and threading model on the
cluster of Multi-core platforms is becoming popular to enhance the performance of your application.
Several factors such as
proper use of threading, understanding of how threads operate, thread safety, Mesage Passing Library Calls (MPI),
algorithm used for your application,
the threading application programming interface (API), the compiler runtime environment, and the number
of multi-cores used for your application play an important role to develop the application based on mixed
programming environment.
Intel Threading Building Blocks (TBB) is a library that helps you leverage programming on multi-core processors
without having to be a threading expert. It offers a rich and complete approach to expressing parallelism
in a C++ program. It is a library that helps you leverage multi-core processor performance without having
to be a threading expert. Threading Building Blocks represents a higher-level, task-based parallelism that
abstracts platform details and threading mechanisms for performance and scalability. Threading Building
Blocks helps you create applications that reap the benefits of new processors with more and more cores as
they become available.
Message passing code written in MPI are obviously portable and should transfer easily to clustered SMP systems. While
message passing is required to communicate between boxes, it is not immediately clear that this is the most
efficient parallelisation technique within an SMP box. In theory a shared memory model
such as OpenMp should offer a more efficient parallelisation strategy within an SMP box.
Hence a combination of shared memory and message passing parallelisation paradigms
within the same application (mixed mode programming) may provide a more efficient parallelisation strategy
than pure MPI.
While mixed code may involve other programming languages such as High Performance Fortran (HPF) and
POSIX threads. Mixed MPI
and TBB codes are likely to represent the most widespread use of mixed mode programming on cluster of
multi-core processors in future.
While SMP clusters or cluster of mulit-core processors offer the greatest reason for developing mixed mode code, both the OpenMP and MPI
paradigms have different advantages and disadvantages and by developing such a model
these characteristics might even be exploited to give the best performance on a single SMP /Multi-core
system.
Thread Safety in MPI-TBB
Although a large number of MPI implementations are thread-safe, mixed mode programming cannot be guaranteed.
To ensure the code is portable allMPI calls should be made within thread sequential regions of the code.
This often creates little problem as the
majority of codes involve the OpenMP /TBB parallelisation occurring beneath the MPI parallelisation and hence
the majority of MPI calls occur outside the OpenMP /TBB parallel regions.
When writing a mixed mode application it is important
to consider how each paradigm carries out parallelisation, and whether
combining the two mechanisms provides and optimal parallelisation strategy.
|
|
Message Passing Interface
A proposed standard Message Passing Interface (MPI) is originally designed for writing applications and libraries for distributed memory environments. The main advantages of establishing a message-passing interface for such environments are portability and ease of use, and a standard memory-passing interface is a key component in building a concurrent computing environment in which applications,software libraries, and tools can be transparently ported between different machines.
The Message Passing Interface (MPI) is the most widely used of the new standards. It is not a new programming language; rather it is a library of subprograms that can be called from C and Fortran programs. An open, international forum consisting of representatives from industry, academia, and government laboratories developed it. It has rapidly received widespread acceptance because it has been carefully designed to permit maximum performance on a wide variety of systems, and it is based on message passing, one of the most powerful and widely used paradigms for programming parallel systems (MPI forum 1994,). MPI is a good example of using a few independent (orthogonal) language features. MPI is based on four main concepts that are orthogonal to one another: data type, communication operations,communicator, and virtual topology. Any combination of the fouris valid. This orthogonal independence brings a multiplicative effect.
The current version of MPI assumes that processes are statically allocated; i.e., the number of processes is set at the beginning of program execution, and no additional processes are created during execution. Each processes is assigned a unique integer rank in the range 0, 1, 2, ..,p-1, where p is the number of processes. This approach to programming MIMD systems is called single-program multiple data (SPMD).In SPMD programs, the effect of running different programs is obtained by the use of conditional branches within the source code.
A nice feature of the MPI design is that MPI provides a powerful
functionality based on four orthogonal concepts. These four
concepts in MPI are message data types, communicators,
communication operations, and virtual topology.
|
Mixed Mode MPI-OpenMP Programming Concepts
|
|
By utilizing a mixed mode-programming model we should be able to take advantage of the benefits of both models. For example
a mixed mode program may allow us to make use of the explicit control data placement policies of MPI with the finer grain parallelism of OpenMP/TBB.The majority of
mixed mode applications involve a hierarchical model, MPI parallelisation occurring at the top level, and OpenMP/TBB parallelisation occurring below.
For example, Figure 1 shows a 2D grid which has been divided between four MPI processes.
In the mixed mode programming concept, MPI should be thread safe. If MPI is not thread safe, the program which is non-blocking MPI library calls and OpenMP
in certain order may give wrong results. Special care is needed while using MPI library calls in mixed mode programmig with OpenMP/TBB to avoid race conditions
or to get correct results.
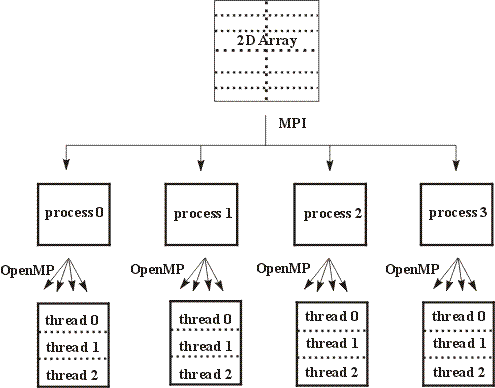 Figure 1: Schematic representation of a hierarchical mixed mode progamming model for a 2D array.
Figure 1: Schematic representation of a hierarchical mixed mode progamming model for a 2D array.
These sub-arrays have then been further divided between three OpenMP/TBB threads. This model closely maps to the architecture of an SMP cluster
or cluster of Multi-core processors,the MPI parallelisation occurring between the SMP (Multi-Core) boxes and the OpenMP/TBB parallelisation within the boxes.
Message passing Could be used within a code when this is relatively simple to implement and shared memory parallelism used where message
passing is difficult. Most of the manufacturers provide extended versions of their communication library for clusters of multiprocessors,
existing MPI codes can be directly used with a unified MPI model. The alternative is mixing MPI with a shared memory model such as OpenMP /TBB. In that case,
different possibilities exist,which must be compared according to the performance and programming effort tradeoff.
Programming efforts for mixing MPI and OpenMP (TBB)
(A) Fine-grain parallelisation
From an existing MPI code, the simplest approach is the incremental one:
It consists of TBB parallelisation of the loop nests in the computation part of the MPI code. This approach is also called TBB fine-grain or loop
level parallelisation. Several options can be used according to
- The programming effort
- The choice of the loop nests to parallelise
Several levels of programming effort can be used. First possibility consists in parallelising loop nests in the computation part of the MPI code without any manual optimization. Only the correctness of the parallel version versus the sequential version semantic is checked. But the incremental approach can be significantly improved by applying several manual optimizations (loop permutation, loop exchange,use of temporary variables). These optimizations are required
- To transform non parallel loop nests into parallel ones.
- To improve the parallel efficiency by avoiding false sharing or reducing the number of
synchronization points (critical sections, barriers).
Another issue is the choice of the loop nests to parallelise. One option is to parallelise all loop nests. This option has two drawbacks:
- It increases the programming effort.
- The parallelisation loop nests that doesn't contribute significantly to the global execution time can be counter-productive.
The alternative option consists in selecting by profiling the loop nests that contribute significantly to the global execution time.
(B) Coarse-grain parallelisation
Instead of applying a two level parallelisation (process level and loop level), another currently investigated approach is the
coarse-grain OpenMP /TBB SPMD parallelisation. In this approach, OpenMP or TBB is still used to take advantage of the shared memory inside the SMP nodes (
Multi-core Processor systems )
but a SPMD programming style is used instead of the traditional shared memory multi-thread approach.
In this mode, OpenMP or TBB is used to spawn N threads in the main program, having each thread act similarly to a MPI process.
The OpenMP or TBB PARALLEL directive is used at the outermost level of the program.
The principle is to spawn the threads just after the spawn of the MPI processes (some initializations may separate the two spawns). As for the message passing SPMD approach, the programmer must take care of several issues:
- Array distribution among threads
- Work distribution among threads
- Coordination between threads
Since the array distribution is done assuming a shared memory, the distribution of the array only concerns
the attribution of different array regions to the different running threads.
For maximum performance, these regions should not overlap for write references.
The work distribution is made according to the array distribution.
|
Basic MPI 1.X library Calls
|
Brief Introduction to MPI 1.X Library Calls :
Most commonly used MPI Library calls in FORTRAN/C -Language
have been explained below.
-
Syntax : C
MPI_Init(int *argc, char **argv);
Syntax : Fortran
MPI_Init(ierror)
Integer ierror
Initializes the MPI execution environment
This call is required in every MPI program and must be the first MPI call. It
establishes the MPI "environment". Only one invocation of MPI_Init can occur in each
program execution. It takes the command line arguments as parameters. In a FORTRAN call to
MPI_Init the only argument is the error code. Every Fortran MPI subroutine returns an error
code in its last argument, which is either MPI_SUCCESS or an implementation-defined error code.
It allows the system to do any special setup so that the MPI library can be used.
-
Syntax : C
MPI_Comm_rank (MPI_Comm comm, int rank);
Syntax : Fortran
MPI_Comm_rank (comm, rank, ierror)
integer comm, rank, ierror
Determines the rank of the calling process in the communicator
The first argument to the call is a communicator and the rank of the process is returned
in the second argument. Essentially a communicator is a collection of processes
that can send messages to each other. The only communicator needed for basic programs
is MPI_COMM_WORLD and is predefined in MPI and consists of the processees running
when program execution begins.
-
Syntax : C
MPI_Comm_size (MPI_Comm comm, int num_of_processes);
Syntax : Fortran
MPI_Comm_size (comm, size, ierror)
integer comm, size, ierror
Determines the size of the group associated with a communicator
This function determines the number of processes executing the program. Its first argument
is the communicator and it returns the number of processes in the communicator in its second
argument.
-
Syntax : C
MPI_Finalize()
Syntax : Fortran
MPI_Finazlise(ierror)
integer ierror
Terminates MPI execution environment
This call must be made by every process in a MPI computation. It terminates the MPI "environment",
no MPI calls my be made by a process after its call to MPI_Finalize.
-
Syntax : C
MPI_Send (void *message, int count, MPI_Datatype
datatype, int destination, int tag,
MPI_Comm comm);
Syntax : Fortran
MPI_Send(buf, count, datatype, dest, tag, comm, ierror)
<type> buf (*)
integer count, datatype, dest, tag, comm, ierror
Basic send (It is a blocking send call)
The first three arguments descibe the message as the address,count and the datatype.
The content of the message are stored in the block of memory refrenced by the address.
The count specifies the number of elements contained in the message which are of
a MPI type MPI_DATATYPE. The next argument is the destination, an integer specifying
the rank of the destination process.
The tag argument helps identify messages.
-
Syntax : C
MPI_Recv (void *message, int count, MPI_Datatype
datatype, int source, int tag, MPI_Comm
comm, MPI_Status *status)
Syntax : Fortran
MPI_Recv(buf, count, datatype, source, tag, comm, status, ierror)
<type> buf (*)
integer
count, datatype, source, tag, comm, status, ierror
Basic receive ( It is a blocking receive call)
The first three arguments descibe the message as the address,count and the datatype.
The content of the message are stored in the block of memory referenced by the address.
The count specifies the number of elements contained in the message which are of a MPI
type MPI_DATATYPE. The next argument is the source which specifies the rank of the sending
process. MPI allows the source to be a "wild card". There is a predefined constant
MPI_ANY_SOURCE that can be used if a process is ready to receive a message from any
sending process rather than a particular sending process. The tag argument helps identify
messages. The last argument returns information on the data that was actually received.
It references a record with two fields - one for the source and the other for the tag.
-
Syntax : C
MPI_Sendrecv (void *sendbuf, int sendcount, MPI_Datatype
sendtype, int dest, int sendtag, void
*recvbuf , int recvcount, MPI_Datatype recvtype, int
source, int recvtag, MPI_Comm comm, MPI_Status
*status);
Syntax : Fortran
MPI_Sendrecv (sendbuf, sendcount, sendtype, dest, sendtag, recvbuf,
recvcount, recvtype, source, recvtag, comm, status, ierror)
<type> sendbuf (*), recvbuf (*)
integer
sendcount, sendtype, dest, sendtag, recvcount, recvtype, source, recvtag
integer
comm, status(*), ierror
Sends and recevies a message
The function MPI_Sendrecv, as its name implies, performs both a send ana a
receive. The parameter list is basically just a concatenation of the parameter
lists for the MPI_Send and MPI_Recv. The only difference is that the
communicator parameter is not repeated. The destination and the source
parameters can be the same. The "send" in an MPI_Sendrecv can be matched by an
ordinary MPI_Recv, and the "receive" can be matched by and ordinary MPI_Send.
The basic difference between a call to this function and MPI_Send followed by
MPI_Recv (or vice versa) is that MPI can try to arrange that no deadlock occurs
since it knows that the sends and receives will be paired.
-
Syntax : C
MPI_Isend (void* buf, int count, MPI_Datatype
datatype, int dest, int tag, MPI_Comm
comm, MPI_Request *request)
Syntax : Fortran
MPI_Isend (buf, count, datatype, dest, tag, comm, request, ierror)
<type> buf (*)
integer
count, datatype, dest, tag, comm, request, ierror
Begins a nonblocking send
MPI_Isend is a nonblocking send. The basic functions in MPI for starting
non-blocking communications are MPI_Isend. The "I" stands for "immediate,"
i.e., they return (more or less) immediately.
-
Syntax : C
MPI_Irecv (void* buf, int count, MPI_Datatype
datatype, int source, int tag, MPI_Comm
comm, MPI_Request *request)
Syntax : Fortran
MPI_Irecv (buf, count, datatype, source, tag, comm, request,
ierror)
<type> buf (*)
integer
count, datatype, source, tag, comm, request, ierror
Begins a nonblocking send
MPI_Irecv begins a nonblocking receive. The basic functions in MPI for starting
non-blocking communications are MPI_Irecv. The "I" stands for "immediate,"
i.e., they return (more or less) immediately.
-
Syntax : C
MPI_Wait (MPI_Request *request, MPI_Status *status);
Syntax : Fortran
MPI_Wait (request, status, ierror)
integer request, status (*), ierror
Waits for a MPI send or receive to complete
MPI_Wait waits for an MPI send or receive to complete. There are variety of functions
that MPI uses to complete nonblocking operations. The simplest of these is
MPI_Wait. It can be used to complete any nonblocking operation. The request
parameter corresponds to the request parameter returned by MPI_Isend or
MPI_Irecv.
-
Syntax : C
MPI_Bcast (void *message, int count,
MPI_Datatype
datatype, int root, MPI_Comm comm)
Syntax : Fortran
MPI_Bcast(buffer, count, datatype, root, comm, ierror)
<type> buffer (*)
integer count, datatype, root, comm, ierror
Broadcast a message from the
process with rank "root" to all other processes of the group
It is a collective communication call in which a single process sends same data
to every process. It sends a copy of the data in message on process root
to each process in the communicator comm. It should be called by all
processors in the communicator with the same arguments for root and comm.;
-
Syntax : C
MPI_Scatter ((void *send_buffer, int send_count,
MPI_DATATYPE send_type, void *recv_buffer,
int recv_count, MPI_DATATYPE recv_type, int
root, MPI_Comm comm);
Syntax : Fortran
MPI_Scatter(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype,
root , comm, ierror)
<type> sendbuf (*), recvbuf (*)
integer
sendcount, sendtype, recvcount, recvtype, root , comm, ierror
Sends data from one process to all other processes in a group
The process with rank root distributes the contents of send_buffer
among the processes. The contents of send_buffer are split into p
segments each consisting of send_count elements. The first
segment goes to process 0, the second to process 1 ,etc. The send arguments are
significant only on process root.
-
Syntax : C
MPI_Scatterv (void* sendbuf, int *sendcounts,
int *displs, MPI_Datatype sendtype, void*
recvbuf, int recvcount, MPI_Datatype recvtype, int
root, MPI_Comm comm)
Syntax : Fortran
MPI_Scatterv (sendbuf, sendcounts, displs, sendtype, recvbuf, recvcount,
recvtype, root, comm, ierror)
<type> sendbuf (*), recvbuf (*)
integer
sendcounts (*), displs (*), sendtype, recvcount, recvtype, root, comm, ierror
Scatters a buffer in different/same size of parts to all processes
in a group
A simple extension to MPI_Scatter is MPI_Scatterv.
MPI_Scatterv allows the size
of the data being sent by each process to vary.
-
Syntax : C
MPI_Gather (void *send_buffer, int send_count,
MPI_DATATYPE send_type, void *recv_buffer,
int recv_count, MPI_DATATYPE recv_type, int
root, MPI_Comm comm)
Syntax : Fortran
MPI_Gather(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype,
root, comm, ierror)
<type> sendbuf (*), recvbuf (*)
integer
sendcount, sendtype, recvcount, recvtype, root, comm, ierror
Process gathers together values from a group of tasks
Each process in comm sends the contents of send_buffer to the
process with rank root. The process root concatenates the
received data in the process rank order in recv_buffer. The
receive arguments are significant only on the process with rank root. The
argument recv_count indicates the number of items received from
each process - not the total number received.
-
Syntax : C
MPI_Gatherv (void* sendbuf, int sendcount, MPI_Datatype
sendtype, void *recvbuf, int *recvcounts, int
*displs, MPI_Datatype recvtype, int root, MPI_Comm
comm)
Syntax : Fortran
MPI_Gatherv (sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs,
recvtype, root, comm, ierror)
<type> sendbuf (*), recvbuf (*)
integer
sendcount, sendtype, recvcounts (*), displs (*), recvtype, root, comm,
ierror
Gathers into specified locations from all processes
in a group
A simple extension to MPI_Gather is MPI_Gatherv. MPI_Gatherv
allows the size of
the data being sent by each process to vary.
-
Syntax : C
MPI_Reduce (void *operand, void *result, int
count, MPI_Datatype datatype, MPI_Operator
op, int root, MPI_Comm comm);
Syntax : Fortran
MPI_Reduce(sendbuf, recvbuf, count, datatype, op, root, comm,ierror)
<type> sendbuf (*), recvbuf (*)
integer count, datatype, op, root, comm, ierror
Reduce values on all processes to a single value
MPI_Reduce combines the operands stored in *operand using operation op and
stores the result on *result on the root. Both operand and result
refer count memory locations with type datatype. MPI_Reduce must
be called by all the process in the communicator comm, and count, datatype
and op must be same on each process.
-
Syntax : C
MPI_Allgather (void *send_buffer, int send_count,
MPI_DATATYPE
send_type, void *recv_buffer, int recv_count,
MPI_Datatype recv_type, MPI_Comm comm)
Syntax : Fortran
MPI_Allgather(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype,
comm, ierror)
<type> sendbuf(*), recvbuf(*)
integer
sendcount, sendtype, recvcount, recvtype, comm, ierror
Gathers data from all processes and distribute it to all
MPI_Allgather gathers the contents of each send_buffer on each process.
Its effect is the same as if there were a sequence of p
calls to MPI_Gather, each of which has a different process acting as a root.
-
Syntax : C
MPI_Alltoall (void* sendbuf, int sendcount,
MPI_Datatype
sendtype, void* recvbuf, int recvcount, MPI_Datatype
recvtype, MPI_Comm comm)
Syntax : Fortran
MPI_Alltoall (sendbuf, sendcount, sendtype, recvbuf, recvcount,
recvtype, comm, ierror)
<type> sendbuf (*), recvbuf (*)
integer
sendcount, sendtype, recvcount, recvtype, comm, ierror
Sends distinct collection of data from all to all processes
MPI_Alltoall is a collective communication operation
in which every process
sends distinct collection of data to every other process. This is an extension
of gather and scatter operation also called as total-exchange.
-
Syntax : C
Double MPI_Wtime( )
Syntax : Fortran
double precision MPI_Wtime
Returns an ellapsed time on the calling processes
MPI provides a simple routine MPI_Wtime( ) that can be used to time programs or
section of programs. MPI_Wtime( ) returns a double precision floating point
number of seconds, since some arbitrary point of time in the past. The time
interval can be measured by calling this routine at the beginning and at the
end of program segment and subtracting the values returned.
-
Syntax : C
MPI_Comm_split ( MPI_Comm old_comm, int split_key, int
rank_key, MPI_Comm* new_comm);
Syntax : Fortran
MPI_Comm_split ( comm, size, ierror)
integercomm, size, ierror
Creates new communicator based on the colors and keys
The single call to MPI_Comm_split creates q new
communicators, all
of them having the same name, *new_comm. It creates a new communicator for each
value of the split_key. Process with the same value of split_key
form a new group. The rank in the new group is determined by the value of rank_key.
If process A and process B call MPI_Comm split with the same value of
split_key, and the rank_key argument passed by process A is less than that
passed by process B, then the rank of A in underlying group new_comm will
be less than the rank of process B. It is a collective call, and it must be
called by all the processes in old_comm.
-
Syntax : C
MPI_Comm_group ( MPI_Comm comm, MPI_Group *group);
Syntax : Fortran
MPI_Comm_group (comm, group, ierror);
integer
comm, group, ierror
Accesses the group associated
with the given communicator
-
Syntax : C
MPI_Group_incl ( MPI_Group old_group, int new_group_size,
int* ranks_in_old_group, MPI_Group*
new_group)
Syntax : Fortran
MPI_Group_incl (old_group, new_group_size, ranks_in_old_group ,
new_group, ierror)
integer
old_group, new_group_size, ranks_in_old_group (*), new_group, ierror
Produces a group by reordering an existing group and taking
only unlisted members
-
Syntax : C
MPI_Comm_create(MPI_Comm old_comm, MPI_Group new_group,
MPI_Comm * new_comm);
Syntax : Fortran
MPI_Comm_create(old_comm, new_group, new_comm, ierror);
integer
old_comm, new_group, new_comm, ierror
Creates a new communicator
Groups and communicators are opaque objects. From a parctical standpoint, this
means that the details of their internal representation depend on the
particular implementation of MPI, and, as a consequence, they cannot be
directly accessed by the user. Rather the user access a handle that refrences
the opaque object, and the objects are manipulated by special MPI functions
MPI_Comm_create, MPI_Group_incl and MPI_Comm_group. Contexts are not explicitly
used in any MPI functions. MPI_Comm_group simply returns the group underlying
the communicator comm. MPI_Group_incl creates a new group from the list of
process in the existing group old_group. The number of process in he new group
is the new_group _size, and the processes to be included are listed in ranks_in
_old_group. MPI_Comm_create associates a context with the group new_group and
creates the communicator new_comm. All of the process in new_group belong to
the group underlying old_comm. MPI_Comm_create is a collective operation. All
the processes in old_comm must call MPI_Comm_create with the same
arguments.
-
Syntax : C
MPI_Comm_create(MPI_Comm old_comm, MPI_Group new_group,
MPI_Comm * new_comm);
Syntax : Fortran
MPI_Comm_create(old_comm, new_group, new_comm, ierror);
integer
old_comm, new_group, new_comm, ierror
Creates a new communicator
Groups and communicators are opaque objects. From a parctical standpoint, this
means that the details of their internal representation depend on the
particular implementation of MPI, and, as a consequence, they cannot be
directly accessed by the user. Rather the user access a handle that refrences
the opaque object, and the objects are manipulated by special MPI functions
MPI_Comm_create, MPI_Group_incl and MPI_Comm_group. Contexts are not explicitly
used in any MPI functions. MPI_Comm_group simply returns the group underlying
the communicator comm. MPI_Group_incl creates a new group from the list of
process in the existing group old_group. The number of process in he new group
is the new_group _size, and the processes to be included are listed in ranks_in
_old_group. MPI_Comm_create associates a context with the group new_group and
creates the communicator new_comm. All of the process in new_group belong to
the group underlying old_comm. MPI_Comm_create is a collective operation. All
the processes in old_comm must call MPI_Comm_create with the same
arguments.
-
Syntax : C
MPI_Cart_create (MPI_Comm comm_old, int
ndims, int *dims, int *periods, int reorder,
MPI_Comm *comm_cart)
Syntax : Fortran
MPI_Cart_create (comm_old, ndims, dims, periods, reorder, comm_cart,
ierror)
integer
comm_old, ndims, dims(*), comm_cart, ierror logical periods(*), reorder
Makes a new communicator to which
topology information has been given in the form of Cartesian Coodinates
MPI_Cart_create creates a Cartersian decomposition of
the processes, with the
number of dimensions given by the number_of_dimensions argument. The user can
specify the number of processes in any direction by giving a positive value to
the corresponding element of dimensions_sizes.
arguments.
-
Syntax : C
MPI_Cart_rank (MPI_Comm comm, int *coords, int
*rank)
Syntax : Fortran
MPI_Cart_rank (comm, coords, rank, ierror)
integer comm, coords (*), rank, ierror
Determines process rank in communicator
given Cartesian location
MPI_Cart_rank returns the rank in the Cartesian communicator
comm of the process
with Cartesian coordinates. So coordinates is an array with order equal to the
number of dimensions in the Cartesian topology associated with comm.
-
Syntax : C
MPI_Cart_coords (MPI_Comm comm, int rank, int
maxdims, int *coords)
Syntax : Fortran
MPI_Cart_coords (comm, rank, maxdims, coords, ierror)
integer
comm, rank, maxdims, coords (*), ierror
Determines process coords in Cartesian
topology given ranks in new Commincator
MPI_Cart_coords takes input as a rank in a communicator,
returns the coordinates
of the process with that rank. MPI_Cart_coords is the inverse to MPI_Cart_Rank;
it returns the coordinates of the processes with rank rank in the Cartesian
communicator comm. Note that both of these functions are local.
-
Syntax : C
MPI_Cart_shift (MPI_Comm comm, int direction,
int disp, int *rank_source, int *rank_dest)
Syntax : Fortran
MPI_Cart_shift (comm, direction, disp, rank_source, rank_dest, ierror)
integer comm, direction, disp, rank_source, rank_dest, ierror
Returns the shifted source and destination
ranks given a shift direction and amount
MPI_Cart_shift returns rank of source and destination
processes in arguments rank_source and rank_dest respectively.
-
Syntax : C
MPI_Cart_sub (MPI_Comm comm, int *remain_dims, MPI_Comm
*newcomm)
Syntax : Fortran
MPI_Cart_sub (old_comm, remain_dims, new_comm, ierror)
integer old_comm, newcomm, ierror
logical remain_dims(*)
Partitions a communicator into subgroups that from
lower-dimensional cartesian subgrids
MPI_Cart_sub partitions the processes in cart_comm into a
collection of disjoint
communicators whose union is cart_comm. Both cart_comm and each new_comm have
associated Cartesian topologies.
-
Syntax : C
MPI_Dims_create (int nnodes, int ndims, int
*dims)
Syntax : Fortran
MPI_Dims_create (nnodes, ndims, dims, ierror)
integer nnodes, ndims, dims(*), ierror
Create a division of processes in the
Cartesian grid
MPI_Dims_create creates a division of processes in a
Cartesian grid. It is
useful to choose dimension sizes for a Cartesian coordinate system.
-
Syntax : C
MPI_Waitall(int count, MPI_Request *array_of_requests,
MPI_Status *array_of_statuses)
Syntax : Fortran
MPI_Waitall(count, array_of_requests, array_of_statuses, ierror)
integer
count, array_of_requests (*), array_of_statuses (MPI_status_size, *), ierrror
Waits for all given communications to
complete
MPI_Waitall waits for all given communications to
complete and to test all or
any of the collection of nonblocking operations.
|
|
Basic TBB Library Templates
|
|
TBB Template devide in Three parts.
Basic algorithms:
1.parallel_for:
parallel_for(blocked_range<T>(begin,end,grainsize),body object)
A parallel_for<Range,Body> represents parallel execution of Body over each value in Range. This template function tbb::parallel_for recursively splits the iteration space into chunks and runs each chunk on a separate thread. A blocked_range<T> is a template class provided by the library. It describes a one-dimensional iteration space over type T. begin and end are the limits of the iteration space. grainsize refers to size of each chunk. Body object is an loop body object, in which operator() process a chunk.
2.parallel_reduce:
parallel_reduce(blocked_range<T>(begin,end,grainsize),body object)
A parallel_reduce<Range,Body> performs parallel reduction of Body over each value in Range. This template function can parallelize the loop if iterations are independent. TBB defines parallel_reduce similar to the parallel_for..
3.parallel_scan:
parallel_scan(blocked_range<T>(begin,end,grainsize),body object)
A parallel_scan<Range,Body> computes a parallel prefix or parallel scan. The template function parallel_scan decides whether and when to generate parallel work. parallel_scan better suited for future systems with more than two cores.
Advanced algorithms:
1.parallel_while:
parallel_while<Body>
A parallel_while<Body> performs parallel iteration over items. The processing to be performed on each item is defined by a function object of type Body. The template class tbb::parallel_while can be used if the end of the iteration space is not known in advance, or the loop body may add more iterations to do before the loop exits.
2.parallel_sort:
void parallel_sort(RandomAccessIterator begin,RandomAccessIterator end,const Compare& comp );
A call to parallel_sort(i,j,comp) sorts the sequence [i,j) using the third argument comp to determine relative orderings.
void parallel_sort(RandomAccessIterator begin,RandomAccessIterator end,const Compare& comp );
A call to parallel_sort(i,j) is equivalent to parallel_sort(i,j,std::less<T>).
parallel_sort provides an unstable sort of the sequence [begin1,end1). This sort is a comparison sort with an average time complexity O(n log n).
3.Pipeline:
class pipeline;
A pipeline represents the pipelined application of a series of filters to a stream of items. Each filter is parallel or serial.
class filter;
A filter represents a filter in a pipeline. A filter is parallel or serial. A parallel filter can process multiple items in parallel and possibly out of order. A serial filter processes items one at a time in the original stream order.
Containers:
1.concurrent_queue:
concurrent_queue<T>
The template class concurrent_queue<T> implements a concurrent queue with values of type T. This is bounded data structure, that permits multiple threads to concurrently push and pop item from the queue.
Pushing is provided by the push method.
Pop is carried by blocking and nonblocking methods.
pop_if_present
It is nonblocking, if the queue is empty, it returns anyway.
Pop
This method blocks until it pops a value.
2.concurrent_vector:
concurrent_vector<T>
A concurrent_vector<T> is a dynamically grow able array of items of type T for which it is safe to simultaneously access elements in the vector while growing it.
3.concurrent_hash_map:
concurrent_hash_map<Key,T,HashCompare>
A concurrent_hash_map<Key,T,HashCompare> is a hash table that permits concurrent accesses. The table is a map from a key to a type T. The HashCompare traits type defines how to hash a key and how to compare two keys. A concurrent_hash_map maps keys to values in a way that permits multiple threads to concurrently access values.
|
Compilation and Execution of MPI-TBB programs
|
|
Compilation, Linking and Execution of MPI-TBB programs. (Refer MPI & TBB
Modules.)
|
|
