hyPACK-2013 : Power-aware Computing & Performance of Application Kernels using GPUs
In the recent past, the energy and power density consumption in modern processors is growing
for HPC applications and these efforts led to design power-aware computer architectures.
With Power dissipation becoming an increasingly serious problem, the modern ARM processors,
GPUs and many-core systems are used for calculation of power consumption and performance of
application kernels. Power measurement for modern GPU Cards and NVIDIA's
Management Library (NVML) through Pthreads.APIs has been used for many application kernels.
Also, the power-off meter which is an external device is also used to measure the total
performance of application on Multi-Core processor system.
GPU accelerated computing systems have drawn the attention of researchers because they
have tremendous computational power and high memory bandwidth, and are inherently well
suited for massively data parallel computation.
While the memory bandwidth and latency issues stall a CPU, a GPU may outperform a CPU
in these aspects. For example the memory bandwidth for modern Nvidia GPU processors is
C2075 is more than 140 GB/s. NVML is a C-based interface for monitoring and managing various states within Nvidia
Tesla GPUs NVML has several functions that can measure characteristics of GPUs, such
as device power, device temperature, unit power, unit temperature, and clock frequency.
Using NVML, we measure power and temperature.
Click here ...... to know more about NVIDIA- NVML-CUDA Power-aware GPU Codes
Nvidia Management Library (NVML) high level utility called nvidia-smi not only provides
a way to measure power but also various other features like the ability to set
ECC (Error Correction Code) to zero if it is not needed, or to monitor memory usage,
among other things.
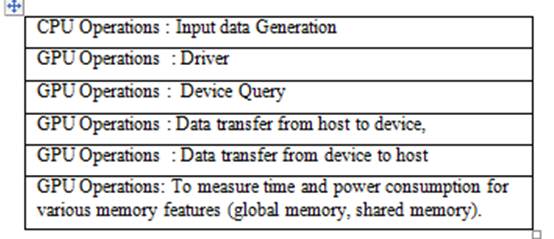
Table I. GPU operations used for measurement of Power Consumption on NVIDIA GPUs
Nvidia Management Library (NVML) high level utility called nvidia-smi not only provides
a way to measure power but also various other features like the ability to set
ECC (Error Correction Code) to zero if it is not needed, or to monitor memory usage,
among other things. NVML can be used to measure power when running the kernel but
since nvidia-smi is a high level utility the rate of sampling power usage is very
low and unless the kernel is running for a very long time we would not notice the
change in power. NVML offers a lot of useful utilities for not only GPUs such as
C2075 but also the Nvidia Tesla C2050 GPU where one would see power in states
rather than in milliwatts. The nvmlDeviceGetPowerUsage function in the NVML
library retrieves the power usage reading for the device, in milliwatts.
This is the power draw for the entire board, including GPU, memory, etc.
The reading is accurate to within a range of +/- 5 watts error with milliwatt
precision. It is only available if power management mode is supported.
The measurement
of CPU and GPU operations have been done independently as a subroutines, indicated in table I
and an average value is considered to estimate the power using NVML library calls for important
GPU operations. Results are validated using total power-watt values for appropriate test-bed.
For system with CUDA carma system and AMD GPUs, power consumption for various GPU operations are
measured using power off meter and other low level benchmarks. On AMD APUs, the power off meter
is used to get the total power consumed for the application.
Mode-6 :
HPC Cluster Applications : Power & Performance:
-
Write your own program for NLA kernel codes and measure the power consumption and performance
(turn around time & throughput) of Benchmarks.
-
Write your own program to measure the total power consumption and performance for
different problem sizes for implementation of PDE solver using
Finite Difference Method (FDM) based on MPI & OpenMP framework.
-
Power-Watt Consumption : Check for Power Consumption on each device with driver
and without driver
-
Power Watt Consumption : Device Query and Memory Check, Memory Bandwidth, Bandwidth
-
Power Watt Consumption : Asynchronous and Overlapping Transfers with Computation
-
Open Source Benchmark Stream Execution - Performance on each GPU
-
SAXPY implementations in CUDA C and Thrust
-
Global and Shared Memory Implementation - Memory Intensive Benchmark
-
Floating Point Benchmark - Global and Shared Memory using CUBLAS library call - DGEMM
-
Floating Point Benchmark - Coalesced Access to Global Memory
-
Application Kernels : Implementation of Poisson Equation solver - CUDA Implementation
-
Application Kernels : Implementation of String Search Algorithms

|
