hyPACK-2013 : Mode-2 (ARM Coprocessor ) Laboratory : Topics
ARM development platform featuring NVIDIA Tegra processors
are being used in HPC. ARM platforms with CUDA parallel programming
toolkit, provides the foundation for developers to build out the ARM HPC application ecosystem.
The CARMA DevKit features the NVIDIA Tegra 3 Quad-core ARM A9 CPU and the NVIDIA Quadro 1000M GPU
with 96 CUDA cores. It offers HPC developers a simple way to create CUDA applications for
GPU-accelerated systems with ARM processors. The topics such as
Tuning and Performance Issues, Power Consumption for Application Kernels, Measurement of Power Consumption - using External Power-Off-Meter, and Programming on ARM processor multi-core processor systems will be discussed.
To understand scalability and performance of selective scientific and engineering or commercial applications, minor or substantive modification of
the hyPACK-2013 software programs may be required. Efforts are on to include State-of-the-Art
Multi-Core Coprocessor ARM Systems as well as NVIDIA CUDA - carma DevKit - GPU based acclerator Servers in hyPACK-2013 laboratory in order to understand measurement of power consumption and performance
issues for large scale application kernels.
|
|
On a Message Passing Cluster, the calculation of power consumption on host and the
device such as NVIDIA GPU or AMD GPU using OpenL and CUDA is required. The calculated
power consumption out of GPU device, data transfer from host to device & device
to host, IO operations as well as initial programming environment will contribute to the total
power consumption of an application.
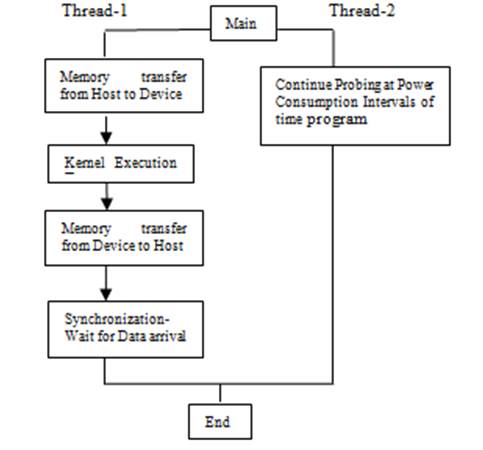
Figure 1. Typical Pthread Model for Calculation of Power Consumption on a system
Figure 1 explains the flow of completion of jobs in which two Pthreads are used. One thread
executes job on GPU accelerator using CUDA or OpenCL and another thread probes the power-off meter
and gathers the reported power values. Also, one thread works
on Xeon multi-coprocessor and records the power values for the entire system. On NVIDIA GPU,
we use NVML library calls with CUDA and OpenCL. Multiple threads can be used to bind multiple
accelerators and coprocessors to record the power consumed and master thread gathers the data and display on the portal. The resolution of power meter is in watts.
In the figure 2, we explore the use of the NVML library APIs to measure real-time power
consumption of BLAS kernels and PDE solver. We analyzed the performance and real-time power
consumption of two fundamental linear algebra algorithms - DGEMM and OpenMP & CUDA,
OpenCL implementation PDE Solver. The nvmlDeviceGetPowerUsage()routine exports the current
power in milliwatt resolution. The power reported is that for the entire board,
including GPU and memory.
The power analyzer electricity watt meter is also used to measure the reported power values.
The Watt's Up power meter is an external measurement device that is plugged into the
system and it provides various measurements via a USB serial connection. The power metrics
collected include average power, voltage, current, and various others. Energy can be derived
based on the average power and time. The results are system-wide and low resolution, with
updates only once a second. Limited memory exists on power-meter and hence the reported power
values for computational performed are collected. Another thread reads the data on a regular
basis, and then returns overall values when an instrumented program requests it.
|
