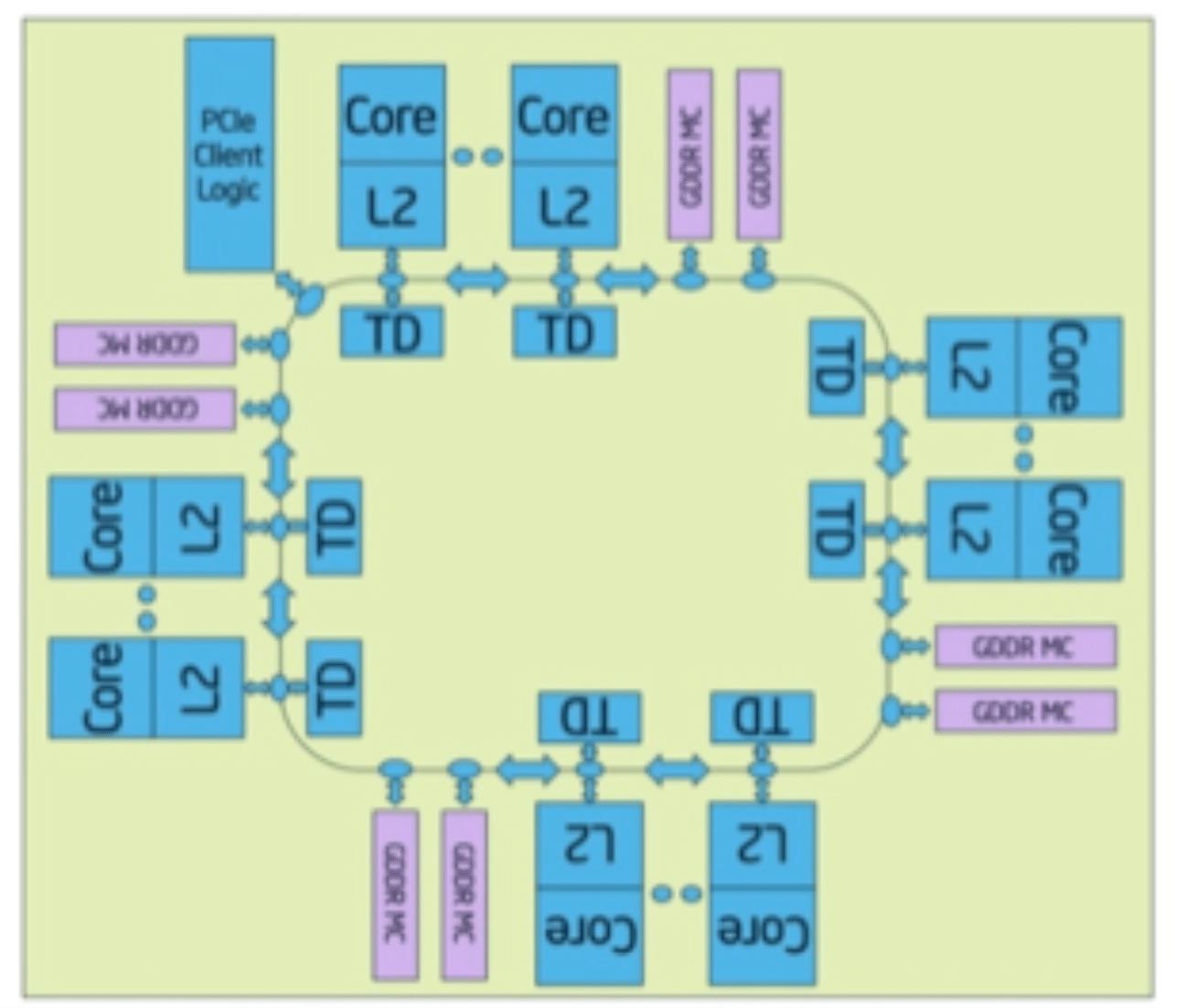
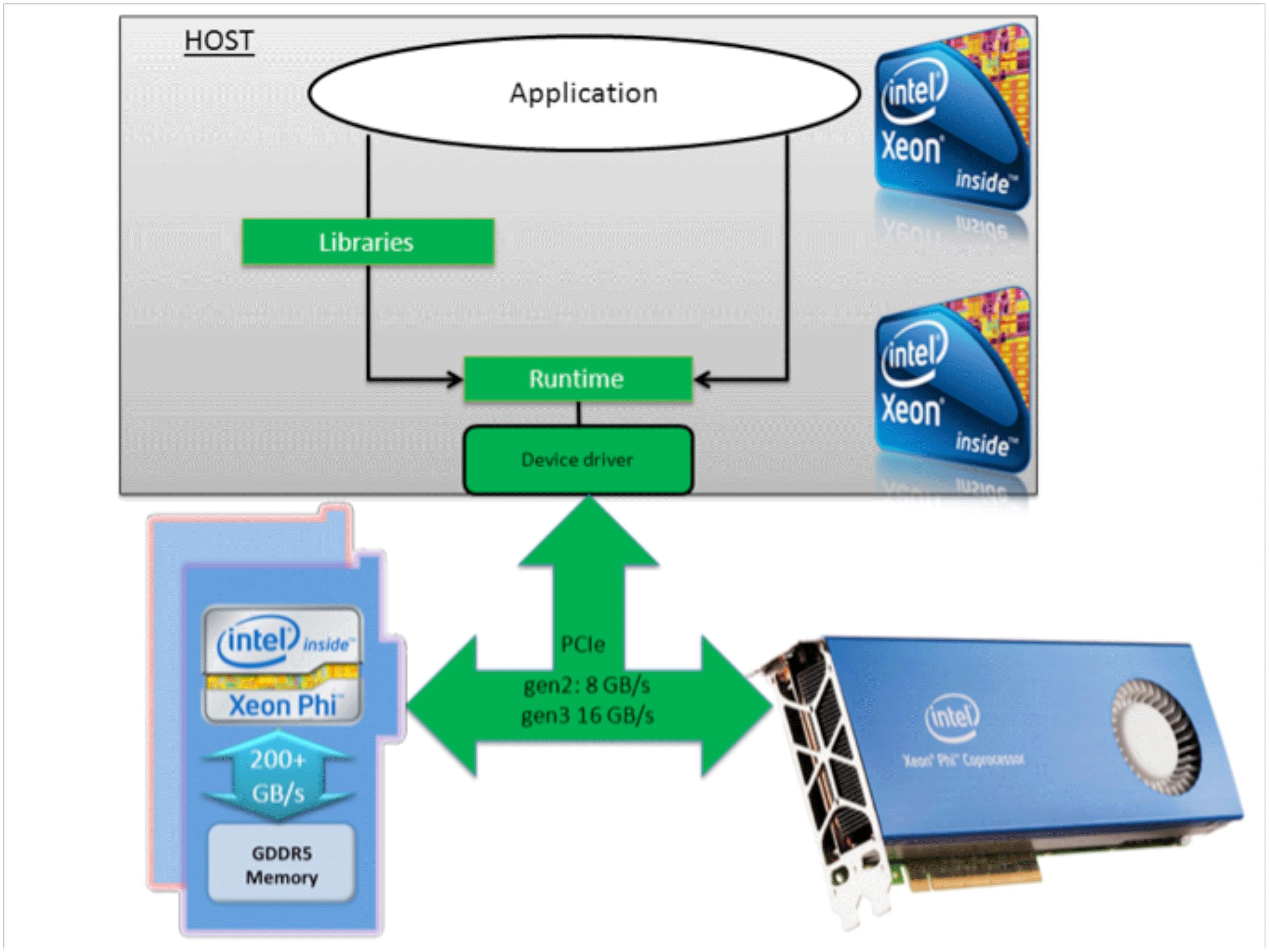
-
Write your own program for NLA kernel codes using auto-parallelisation
features on Xeon-Phi Coprocessors. Analyze the compiler generated optimization reports
for various problem sizes for typical matrix-matrix multiplication algorithms and obtain
maximum achievable performance
-
Write your own program for NLA kernel codes with or without use of Intel MKL
libraries, using Intel Compiler (loop optimization pragmas/directives) Automatic offload &
Compiler-Assisted Offload
-
Write your own software modules for NLA Kernels using compiler auto-parallelization
features of Intel Xeon-Phi and analyze the GAP generated optimization reports. Summarize the performance and scalability issues for various problems size of your code.
-
Write your own Matrix Multiply Code using OpenMP Pragmas based on OpenMP thread affinity on Intel Xeon
Phi Coprocessor.
-
Write your own Matrix Multiply Code using Intel MKL Thread Affinity on Intel Xeon-Phi Coprocessors
-
Write your own software modules for NLA kernels using various clauses
of SIMD Directives. Analyze the Vectorization reports and summarize performance issues
for different problems size.
-
Write your own suite of programs for NLA Kernels (Vector-Vector Addition,
Matrix-Matrix Addition), using
vector aligned data features of Intel Xeon-Phi using declspec(align(*)). Analyze Vectorization
reports & summarize the performance issues for different problems size of your code. You can use
SIMD Directives & IVDEP Directives /PRAGMAS to assist for VECTORIZATION
-
1.6. Obtain the performance for Vector into Vector Multiplication and Matrix into Matrix
Multiplication using Intel MKL Libraries on Intel XeonPhi Coprocessors & Automatic offload
& Compiler-Assisted Offload
-
Write your own software modules for NLA kernels using Intel MKL with (a) compiler
assisted offload (b) Reusing data that already exists in the memory of the coprocessor helps
to reduce transferring data for an example which illustrates how to perform multiple operations
on a single set of input matrices
-
Write your own program for NLA kernels with and without array operations using
vectorization features
-
Write your own program for Matrix-Matrix Multiplication based on Block-partitioning
of input matrices and use the Xeon-Phi Programming Environment features such as (a).
Allocated Persistent Storage on Co-Processor (b). Asynchronous data transfer from the
coprocessor to the processor (c). Double buffers inputs to an offload
-
Write your own program to perform large scale I/O operations and
quantify the overheads.
-
Write your own program to measure copy-memory bandwidth using openMP or Pthreads,
using 8/16/32 cores of Intel Xeon-Phi with different work-loads, and analyze the performance
-
Obtain Performance of Stream OpenMP benchmark on Intel Xeon-Phi and
compare the performance with the output of previous example using different programming paradigms.
-
Write your own program to measure latency, bandwidth and quantify overheads
using MPI point-to-point and Collective communications on Intel Xeon-Phi Coprocessors
in a Message Passing Cluster with different message sizes & analyze the performance
-
Write your own software modules for NLA (SGEMM/ DGEMM) kernels code using openMP
allocated memory on the heap aligned to 64 byte boundary & analyze the performance issues
& scalability issues (Use #pragma vector aligned #pragma ivdep\94 & posix_memalign\94 for
dynamic memory alignment)
-
Write your own program to analyze the CPU time, Xeon-Phi time, CPU-to-Xeon-Phi Data
transfer time and Xeon-Phi-CPU data transfer time and quantify the time taken for
different problem sizes with respect to the number of OpenMP threads used and understand
data transfers over the PCIe bus from the host to the accelerator and vice versa
-
Write your own codes for NLA kernels & PDE Solver using MPI-OpenMP (with Collapse and
without Collapse) and Loop un-rolling (nested loops) with Vectorization (ivdep and
vector aligned) (use OpenMP supported four different kinds of loop scheduling.
-
Write your own program for implementation of PDE solver using
Finite Difference Method (FDM) using OpenMP and MPI. The computations are performed
on host and the Coprocessors
-
Write your own program for implementation of PDE solver using Finite Element Method (FEM) in
two-dimensional regions using MPI OpenMP in which the computations are performed on host
and the Coprocessor. Use features such as Overlap Computation and communication - Asynchronous
Transfer & Double Buffering
-
Write your own program for NLA Kernels and an implementation of PDE solver by FDM
in 2D regions using MPI OpenMP in which the computations are performed using
MIC_KMP_AFFINITY=verbose, granularity = fine, scatter, compact, and gather
-
Write your own program for NLA Kernels and an implementation of PDE solver by FDM
in 2D regions using Performance of Tuning OpenMP codes on
Xeon-Phi Modifying Stack Size.
-
Write your own program for implementation of PDE solver using
Finite Difference Method (FDM) using MPI & OpenMP, combination of MPI OpenMP.
The software module should use larger 2MB pages. The importance of larger pages for
floating-point dominated FDM application is required as it performs array operation the
computations on host and the Coprocessor