hyPACK-2013 Mode 1 : MPI 1.X Collective Comm. & Comp. MPI Lib. Calls
|
Module 2 : MPI programs using Collective communication and Computation library calls and execute on Message Passing
Cluster or Multi Core Systems that support MPI library.
|
|
|
Example 2.1
|
Write MPI program to broadcast message
"Hello world" to all the process .
|
Example 2.2
|
Write MPI program to scatter n integers on p
processes (Assume that n is divisible by p ) .
|
Example 2.3
|
Write MPI Program to gather unequal number of
intergers from each process and obtain the resultant data on the process with rank 0. (Assume that the each process has
unequal number of integers.)
|
Example 2.4
|
Write MPI Program to gather n intgers
from each process and obtain the resultant data on each process.
|
Example 2.5
|
Write MPI Program to perform all-to-all communication of n integers on
p process. (Assume that the each process has n integers where n is divisible by p ).
|
Example 2.6
|
Write MPI Program to compute the sum of
q on
p process and proces with rank 0 prints the resultant sum. (Assume that the each process has q integers
where q is equal to n/p and n is total number of integers on each process).
|
Example 2.7
|
Write MPI program to compute the sum of q
integers on p process and each process prints the resultant sum. (Assume that the each process has
q integers and q is equal to n/p and n is total numbe rof integers)
|
Example 2.8
|
Write MPI Program to compute the funciton pi
using MPI collective communication and computation library calls.
|
| |
|
(Source - References :
Books
Multi-threading
-
[MC-MPI-02], [MCMPI-06], [MCMPI-07], [MCMPI-09], [MC-MPI10], [MCMPI-11],
[MCMTh-12],[MCBW-44], [MCOMP-01])
|
|
Description of Programs - MPI Collecive Comm.
& Comp. Lib. Calls
|
Objective
Write a MPI program to braodcast an integer array A of dimension n on
p processors of cluster using MPI_Broadcast communication
library call.
Description
Process with rank 0 genrates an integer array A of size 24 and braodcast the array to all the process.
Input
Process with rank 0 reads the input data.You have to adhere strictly the following format for the input file.
#Line 1 : Size of the array
#Line 2 : data in order, this means that the data of second entry of the input
array A follows the
first and so on.
24
2 10 3 4 23 14 4 6 8 32 63 86
12 8 3 9 13 4 14 16 18 2 9 86
Output
Each process prints its own n elements of array A.
|
Example 2.2:
|
Description for implementation of MPI program to scatter n integers
using MPI collective communication library calls
(Download source code :
scatter.c
/
scatter.f
)
|
Objective
Write a MPI program to scatter an integer array A of dimension n on
p processors of IBM AIX cluster using MPI_Scatter communication
library calls.
Description
Assume thatn is multiple of p and index of the array A starts
from 0 (as in C-Program). Processor with rank k, k = 0,1, ..., p-1
gets n/p values starting from A[i], i = k*n/p to
(k+1)*n/p - 1.
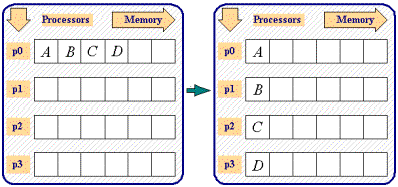
Figure 4 Process p0 performing MPI_Scatter Collective Communication Primitive
Input
Process with rank 0 reads the input data.You have to adhere strictly the following format for the input file.
#Line 1 : Size of the array
#Line 2 : data in order, this means that the data of second entry of the input
array A follows the
first and so on.
24
2 10 3 4 23 14 4 6 8 32 63 86
12 8 3 9 13 4 14 16 18 2 9 86
Output
Each process prints its own n/p elements of array A.
|
 Example 2.3:
Example 2.3:
|
Write MPI Program to gather unequal number of intergers from each process and obtain the resultant
data on the process with rank 0 using collective communication library calls
(Download source code :
gatherv.f
)
(Download Data Files :
gdata0
,
gdata1
,
gdata2
,
gdata3
gdata4
,
gdata5
,
gdata6
,
gdata7
)
|
Objective
Write a MPI program to gather unequal integer array values from each process and store the output values in the global integer
array A of dimension n on p process on a message passing cluster. Use
MPI_gatherv Communication library call in theprogram.
Description :
Each process reads respective input array of different size n/p
from the given input file. The process wit rank 0 accumalates the total number of integers to be recevied
from the each process and allocates memory for the output integer array and performs MPI_gatherv operation.
Input
Each process k reads the input file.You have to adhere strictly the following format for the input
file.
#Line 1 : Size of the local array
#Line 2 : data in order, this means that the data of second entry of the input array A follows the
first and so on.
A sample input file is given below. User can create his own input files
in this format.
Input file for process with rank 0
8
2 4 8 16 32 64 128 256
Each process with rank greater than 0 reades the Input file with differnt total number of integers. You have to adhere strictly
the same format for the input file as given above.
Output
Each process prints the output array A.
|
Example 2.4:
|
Write MPI Program to gather equal number of intergers from each process and obtain the resultant
data on each process using collective communication library calls
(Download source code :
allgather.c
/
allgather.f
)
|
Objective
Write a MPI program to gather values from each process and store the output values in the global integer
array A of dimension n on p process of cluster. Use
MPI_Allgather Communication library call in theprogram.
Description
Assume n be the dimension of an integer input array A , output array B ,
and p be the processes used in the parallel program.
the integer array A [i] of size n/p with known n/p values where varies from 0
to n/p - 1 is given as additional input on processor with rank k
(k = 0,1, ... p-1). Each process reads respective input array of size n/p
from the given input file. You have to adhere strictly the following format for the input file.
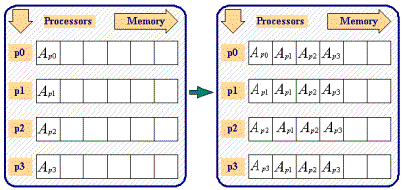 Figure 5 MPI_Allgather Collective Communication Primitive
Figure 5 MPI_Allgather Collective Communication Primitive
Input
Each process k reads the input file.You have to adhere strictly the following format for the input
file.
#Line 1 : Size of the local array
#Line 2 : data in order, this means that the data
of second entry of the input array A follows the
first and so on. A sample input file is given below.
Input file for process 0
6
21 18 54 24 33 69

|
Example 2.5:
|
Write MPI Program perform all-to-all communication of n integers on p process.
(Assume that the each process has n integers where n is divisible by p ).
using MPI_Alltoall collective communication library calls
(Download source code :
alltoall.c
)
|
Objective
Write a MPI program to gather values from each process and store the output values in the global integer
array A of dimension n on p process of cluster. Use
MPI_AllgatherCommunication library call in the program.
Description
Assume n be the dimension of an integer input array A , output array B ,
and p be the processes used in the parallel program. Each process reads input integer array of size n
from the given input file. Assume that n is divisible by p
Figure 5 MPI_Alltoall Collective Communication Primitive
Input
Each process k reads the input file.You have to adhere strictly the following format for the input
file.
#Line 1 : Size of the local array
#Line 2 : data in order, this means that the data of second entry of the input array A follows the
first and so on.
A sample input file is given below. For convenience sake, 4 processes are used in this example.
Input file for process 0
16
21 6 8 45 54 24 33 72 84 12 25 31 46 16 94 65
Output
Each process prints the output array B.
|
Example 2.6:
|
Write MPI program to compute the sum of q
integers on p process and process with rank 0 prints the resultant sum. (Assume that the each process has
q integers and q = n/p and n is total accumalated integers).
Use MPI_Reduce library calls
(Download source code :
reduce.c
/
reduce.f
)
|
Objective
Write a MPI program to find sum of q integers, on p processors of mesaage passing
cluster, using MPI collective communication and computation library call.
Description
MPI collective communication and computation library call, MPI_Reduce is used.
Input
For input data, let each process use its identifying number, i.e. the value of
its rank. For example, process with rank 0 uses the input integer r 0, process
with rank 1 uses the input integer number 1, etc.
Output
Process wih rank 0 prints the final sum.
|
Example 2.7:
|
Write MPI program to compute the sum of q
integers on p process and each process prints the resultant sum. (Assume that the each process has
q integers and q =n/p where n is total number of accumalted integers.
Use MPI_Allreduce library calls.
(Download source code :
allreduce.c
/
allreduce.f
)
(Download source code :
SendSumValue.inp
)
|
Objective
Write a MPI program to find sum of q integers, on p processors of mesaage passing
cluster, using MPI collective communication and computation library call.
Description
In this example MPI collective communication and computation library call, MPI_Allreduce is used.
Input
For input data, let each process use its identifying number, i.e. the value of
its rank. For example, process with rank 0 uses the input intger r 0, process
with rank 1 uses the input integer number 1, etc.
Output
Each process prints the final sum.
|
Example 2.8:
|
Description for implementation of MPI program to comput the value of PI by numerical
integration using MPI collective communication library calls
(Download source code :
pie-collective.c
/
pie-collective.f
)
|
Objective
Write a MPI program to compute the value of pi function by numerical integration of
a function f(x) = 4/(1+x 2 ) between the limits 0 and 1.
Description
There are several approaches to parallelizing a serial program. One approach is
to partition the data among the processes. That is we partition the interval of
integration [0,1] among the processes, and each process estimates local integral over
its own subinterval. The local calculations produced by the individual
processes are combined to produce the final result. Each process sends its integral to process 0,
which adds them and prints the result.
To perform this integration numerically, divide the interval from 0 to 1 into n
subintervals and add up the areas of the rectangles as shown in the Figure 3 (n
= 5). Large values of n give more accurate approximations of pi
. Use MPI Collective communication library calls.
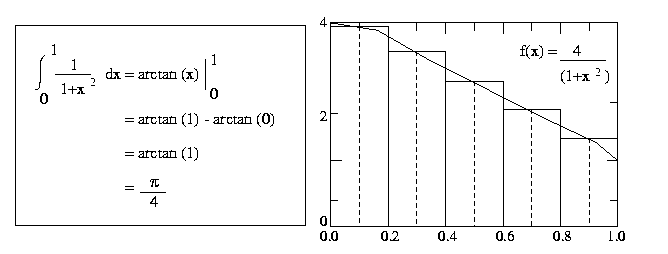
Figure 3 Numerical integration of pie function
We assume that n is total number of subintervals, p is the number
of processes and p < n. One simple way to distribute the total
number of subintervals to each process is to dividen by p. There
are two kinds of mappings that balance the load. One is a block mapping,
partitions the array elements into blocks of consecutive entries and assigns
the block to the processes. The other mapping is a cyclic mapping. It
assigns the first element to the first process, the second element to the
second, and so on. If n > p, we get back to the first process,
and repeat the assignment process for remaining elements. This process is
repeated until all the elements are assigned. We have used a cyclic mapping
for partition of interval [0,1] onto p processes.
Input
Process with rank 0 reads the input parameter n, the number of
intervals as commandline arguement
Output
Process with rank 0 prints the computed value of pi function.
|
| |
|
