|
hyPACK-2013 Mode-2 : GPU Comp. CUDA enabled NVIDIA GPU Prog. |
|
NVIDIA\92s
Compute Unified Device Architecture (CUDA) is a soft-
ware platform for massively parallel high-performance
computing on the company's powerful GPUs. NVIDIA\92s software
CUDA Programming model automatically manages the threads and it is significantly differs from single
threaded CPU code and to some extent even the parallel code. Efficient CUDA programs exploit both
thread parallelism within a thread block and coarser block parallelism across thread blocks. Because only
threads within the same block can cooperate via shared memory and thread synchronization, programmers
must partition computation into multiple blocks.
In all the programs,
CUDA_SAFE_CALL()
that surrounds CUDA API calls is a utility macro that we have provided as part of
Hands-on codes. It simply detects that the call has retuned an error, prints the associated
error message, and exists the application with
ERROR FAILURE
code.
|
CUDA enabled NVIDIA GPU: A Scalable Parallel Programming Model
CUDA is aimed to provide solution for many applications and NVIDIA\92s new GPU which
supports double precision floating point mathematical operations can address broader
class of applications. CUDA is a parallel programming model and software environment
designed to overcome this challenge while maintaining a low learning curve for
programmers familiar with standard programming languages such as C. CUDA requires
programmers to write special code for parallel processing but it doesn't require
them to explicitly manage threads, which simplifies the programming model. CUDA
includes C/C++ Software development tools, functions libraries and a hardware
abstraction mechanism that hides the GPU hardware from developers.
A compiled CUDA program can therefore execute on any number of processor cores,
and only the runtime system needs to know the physical processor count. New CUDA
compatible GPUs are implemented as a set of multiprocessors. Each multiprocessor
has several ALUs (Arithmetic Logic Unit) that, at any given clock cycle, execute
the same instructions but on different data. Each ALU can access (read and write)
the multiprocessor shared memory and the device RAM.
At its core are three key abstractions \96 a hierarchy of thread groups, shared
memories, and barrier synchronization \96 that are simply exposed to the programmer
as a minimal set of extensions to C. CUDA Programming model automatically manages
the threads and it is significantly differs from single threaded CPU code and to
some extent even the parallel code.
The goal of the CUDA programming interface is to provide a relatively simple path
for users familiar with the C programming language to easily write programs for
execution by the device. It consists of:
A runtime library split into:
A host component that runs on the host and provides functions to control and access one or more compute devices from host;
A device component, that runs on the device and provides device-specific functions;
A common component, that provides built-in vector typed and a subset of the C standard library that are supported in both host and device code
A host component that runs on the host and provides functions to control and access one or more compute devices from host;
A device component, that runs on the device and provides device-specific functions;
A common component, that provides built-in vector typed and a subset of the
C standard library that are supported in both host and device code
CUDA assumes that the CUDA threads may execute on a physically separate device
that operates as a co-processor to the host running the C program. This is the case,
for example, when the kernels execute on a GPU and the rest of the C program executes
on a CPU. CUDA also assumes that both the host and the device maintain their own DRAM,
referred to as host memory and device memory, respectively. Therefore, a program manages
the global, constant, and texture memory spaces visible to kernels through calls
to the CUDA runtime. This includes device memory allocation and deallocation, as
well as data transfer between host and device memory.
Function which gets executed on grid is called as kernel function.
A kernel is executed by a grid which contains blocks. These blocks contain
threads. A thread block is a batch of threads that can co-operate
Sharing data through shared memory, and Synchronizing their execution.
Threads from different blocks operate independently.
Because all threads in a grid execute the same kernel function,
they rely on unique coordinates to distinguish themselves from each other
and to identify the appropriate portion of the data to process.
These threads
are organized into a two-level hierarchy using unique
coordinates \96 blockIdx (for block index)
and threadIdx (for thread index)- assigned
to them by the CUDA runtime system.
The blockIdx and threadIdx
appear as builtin, pre-initialized variables that
can be accessed within kernel functions.
When a thread executes the kernel function, references to the
blockIdx
and
threadIdx
variable return the coordinates of the thread. Additional built-in
variables, gridDim
and BlockDim,
provide the dimension of the grid and the
dimension of each block respectively.
The CUDA kernel execution configuration defines the dimensions of a
grid and its blocks.
Unique coordinates in threadIdx and
threadIdx variables allow threads of a grid to
identify themselves and their domains. The threads of a grid can identify themselves
and their domains based on variables blockIdx and threadIdx and these variables
have unique coordinates. These variables are used in CUDA kernel functions
so the threads can properly identify the portion of the data to process
based on different levels of memory that is available in CUDA. Once a grid
is launched, its blocks are assigned to streaming multiprocessors
in arbitrary order, resulting in scalability of CUDA applications.
Importantly, the threads in different blocks to synchronize with each other
are to terminate the kernel and start a new kernel for the activities after
the synchronization point.
Basic CUDA Definitions :
Host : : Refer to the CPU and the system\92s memory as the host
Device : : Refer to the GPU and its memory
Kernel : : A function that executes on the device is typically called a kernel.

Simple Program Kernel Call :
The program given below, includes important additions to the simple sequential code to
make “CUDA enabled Program“.
-
A empty function named kernel()
qualified with _global_
- A call to empty function, written in the form as
<<<1,1>>>
In Linux system, GNU gcc
compiles the code on host and nvcc
gives the function a
kernel()
to the complier
that handles device code and
main()
to the host compiler. instead of the host. Here, the calling the
device code from the host code is important and it is similar to host-function calls.
The angle brackets denote arguments that are passed to the runtime system. These parameters are not
arguments to the device code but are parameters that will influence how the runtime will launch the
device code. Arguments to the device code itself passed within the parentheses.
|
|
The first CUDA parallel program is “Hello World” program,
which simply prints the
message “Hello World ”".
The program calls function
kernel()
as explained above.
|
|
Example Program : A Kernel Call Program
|
|
#include <stdio.h>
#include <cuda.h>
_global_ void kernel (void) {
}
int main ( void ) {
kernel <<< 1,2 >>>();
Printf ( " Hello World \n " );
return 0;
}
|
|
Passing Parameters - Allocation of Memory & Pointers
-
Parameters :
Pass parameters to a kernel similar to any C function in standard C. These parameters need
to get from the host to device at run-time and the runtime system
takes care of these parameter definitions.
-
Allocate Memory:
Allocate memory to do useful work on a device, such as return value to the host.
Allocation of memory using cudaMalloc() is similar to standard C call malloc(),
but it tells the CUDA runtime to allocate the memory on the device.
-
First argument is a pointer to hold the address of the newly allocated memory.
Second parameter is the size of the allocation.
-
CUDA_SAFE_CALL() that surrounds these calls is a utility macro which detects that the call
has returned an error, prints the associated error message and exists the application in
“clean” fashion with an EXIT_FAILURE code.
|
|
Many other error-handling checks are required in production code.
The following program performs addition of two values in which data transfer from host to
device and device to host are performed. Here, the parameters to a kernel are passed and memory
is allocated on host and device.
The second CUDA parallel program is focused on"passing parameters to a kernel and
allocate memory on a device". It performs addition of two values and
the program calls function
kernel()
as given in the function
_global_ void add.
The description of program is as follows:
|
|
Example Program : A Kernel - Passing Parameters & Memory Allocation
|
|
#include <stdio.h>
#include <cuda.h>
_global_ void add (
int a,
int b,
int *c
) {
*c = a + b;
}
/* Utility Macro : CUDA SAFE CALL */
void
CUDA_SAFE_CALL( cudaError_t call)
{
cudaError_t ret = call;
switch(ret)
{
case cudaSuccess:
break;
default :
{
printf(" ERROR at line :%i.%d' ' %s\n",
__LINE__,ret,cudaGetErrorString(ret));
exit(-1);
break;
}
}
}
int main ( void ) {
int c;
int *dev_c;
CUDA_SAFE_CALL( cudaMalloc( (void**)&dev_c, sizeof
(int) ) );
add <<< 1,1 >>>(2,3,dev_c);
CUDA_SAFE_CALL(cudaMemcpy(
&c,
dev_c,
sizeof
(int),
cudaMemcpyDeviceToHost) );
Printf("2 + 3 %d \n ", c);
cudaFree( dev_c);
return 0;
}
|
|
The second CUDA parallel program is focussed on “passing parameters to a kernel and
allocate memory on a device”". It performs addition of two vlaues and
the program calls function
kernel()
as given in the function
_global_ void add.
Responsibility of programmer : The programmer should aware of restrictions on the usage of
device pointers which are summarized as follows.
-
Pass pointers allocated with
cudaMalloc()
to functions that execute on the device
-
Use pointers allocated with
cudaMalloc()
to read or write memory from code that executes on
the device.
-
Pass pointers allocated with
cudaMalloc()
to read or write memory from code that executes on
the device.
-
Cannot use pointers allocated with
cudaMalloc()
to read or write memory from code that executes
on the host.
To free memory for allocated with
cudaMalloc(),
use a call
cudaFree().
To access device memory \96 by using device pointers from within device code and by using calls to
cudaMemcpy() from host code.
The last parameter to
cudaMemcpy() is
cudaMemcpyDeviceToHost instructing
the runtime that the source pointer is a device pointer and the destination pointer is a
host pointer.
cudaMemcpyHostToDevice instructing
the source data is on the host and the destination is an address on the device.
Also, one can specify
cudaMemcpyDeviceToDevice
which indicates both pointers are on the device.
Querying Devices
An easy interface to determine the information such as to find mechanism for determining
which devices (if any) are present and what capabilities each device supports is provided.
First, to get count of how many CUDA devices in the system are built on CUDA Architecture
call the API
cudaGetDeviceCount().
After calling
cudaGetDeviceCount(),
then iterate through the devices and query relevant information about each device.
The CUDA runtime returns device properties in a structure of type
cudaDeviceProp.
As of CUDA 4.1 & CUDA 5.0, the
cudaDeviceProp
structure contains the necessary information and
most of the information in
cudaDeviceProp
is self explanatory and commonly used CUDA device properties.
The description of third example program is focused on device properties as given below. :
|
|
#include <stdio.h>
#include <time.h>
#include <cuda.h>
#define KB 1024
/* To indicate results in KiloBytes */
/* Utility Macro : CUDA SAFE CALL */
void
CUDA_SAFE_CALL( cudaError_t call)
{
cudaError_t ret = call;
switch(ret)
{
case cudaSuccess:
break;
default :
{
printf(" ERROR at line :%i.%d' ' %s\n",
__LINE__,ret,cudaGetErrorString(ret));
exit(-1);
break;
}
}
}
int main ( void ) {
int count;
cudaDeviceProp prop;
CUDA_SAFE_CALL(cudaGetDeviceCount( &count) );
for(int i = 0; i < count; index++) {
CUDA_SAFE_CALL( cudaGetDeviceProperties( &prop, i) );
printf("Information about the device \t: %d\n", count);
printf("Name \t\t\t\t: %s\n",prop.name);
printf("Compute capability \t\t: %d.%d\n",
prop.major, prop.minor);
printf("Clock rate \t\t\t: %d\n", prop.clockRate);
printf("Device overlap \t\t\t: ");
if (prop.deviceOverlap)
printf("ENABLED \n");
else
printf("DISABLED\n");
printf("Kernel execution timeout \t: ");
if
(prop.kernelExecTimeoutEnabled)
printf("ENABLED\n");
else
printf("DISABLED\n");
printf("Total global memory \t\t: %ld MB\n",
(prop.totalGlobalMem/KB)/KB);
printf("Total constant memory \t\t: %ld\n",
prop.totalConstMem);
printf("Maximum memory pitch \t\t: %ld\n", prop.memPitch);
printf("Texture alignment \t\t: %ld\n",
prop.textureAlignment);
printf("Multiprocessor count \t\t: %d\n",
prop.multiProcessorCount);
printf("Shared memory per MP \t\t: %ld KB\n",
prop.sharedMemPerBlock/KB);
printf("Registers per MP \t\t: %ld\n",
prop.regsPerBlock);
printf("Threads in warp \t\t: %d\n", prop.warpSize);
printf("Maximum threads per dimension \t: %d\n",
prop.maxThreadsPerBlock);
printf("Maximum thread dimension \t: (%d, %d, %d)\n",
prop.maxThreadsDim[0], prop.maxThreadsDim[1],
prop.maxThreadsDim[2]);
printf("\n\n\n");
}
return 0;
}
|
CUDA Device Structure
struct cudaDevice Prop {
char name[256];
size_t totalGlobalMem;
size_t sharedMemBlock;
int regsPerBlock;
int warpSize;
size_t memPitch;
int maxThreadsPerBlock;
int maxThreadsDim[1];
int maxGridSize[3];
size_t totalConstMem;
int major;
int minor;
int clockRate;
size_t texturealignment;
int deviceOverlap;
int multiProcessorcount;
int KernelExecutionTimeoutEnabled;
int integrated;
int canMapHostMemory;
int computeMode;
int maxTexture1D;
int maxTexture2d[2];
int maxTexture3d[3];
int maxTexture2dArray[3];
int concurrentKernels;
}
|
CUDA Device Properties (Refer NVIDIA CUDA Programming Guide)
|
Device Property
|
Description
|
|
char name [256];
|
An ASCII string indentifying the device [e.g., GeForce GTX 280"]
|
|
size_t totalGlobalMem
|
The amount of global memory on the devices in bytes
|
|
size_t shareMemPerBlock
|
The maximum amount of shared memory a single block may use
in bytes
|
|
int regsPerBlock
|
The number of 32-bit registers available per block
|
|
int warpSize
|
The number of threads in a warp
|
|
size_t memPitch
|
The maximum pitch allowed for memory copies in bytes.
|
|
int maxThreadsPerBlock
|
The maxmum number of threads that a block may contain
|
|
int maxThreadsDim[3]
|
The number of blocks allowed along each dimneison of a grid
|
|
size_t totalConstMem
|
The amount of avialable constant memory
|
|
int major
|
The major revision of the device's compute capability
|
|
int minor
|
The minor revision of the device's compute capability
|
|
Global Memory size :
|
1073741824
|
|
size_t textureAlignment
|
The device's requirement for texture alignment
|
|
int deviceOverlap
|
A bollean value representing whether the device can
simultaneously perform a cudaMemcpy() and kernel execution
|
|
int multiProcessorCount
|
The number of multiprocessors on the device
|
|
int kernelExecTimeoutEnabled
|
A bollean value representing whether there is a runtime limit
for kernels executed on this device
|
|
int integrated
|
A bollean value representing whether the device is an integrated
GPI (i.e., part of the chipset and not a discrete GPU)
|
|
int canMapHostMemory
|
A bollean value repesenting whether the device can map host
memory into the CUDA device addres space.
|
|
int computeMode
|
A vlaue representing the device's computing mode default, exclusive
or, prohibited
|
|
int maxTexture1D
|
The maximum size supported for 1D textures
|
|
int maxTextture2D[2]
|
The maximum dimensions supported for 2D textures
|
|
int maxTextture3D[3]
|
The maximum dimensions supported for 3D textures
|
|
int maxTextture2DArray[3]
|
The maximum dimensions supported for 2D texture arrays
|
|
int concurrentKernels
|
A bollean value repesenting whether the device supports
executing multiple kernels within the same context
simultaneously.
|

|
Using Device Properties : Program
An easy interface to determine the information such as to find mechanism for determining
which devices (if any) are present and
what capabilities each device supports is provided.
First, to get count of how many CUDA devices in the system are built on CUDA Architectture
call the API
cudaGetDeviceCount().
After calling
cudaGetDeviceCount(),
then iterate through the devices and query relevant information about each device.
The CUDA runtime returns device properties in a structure of type
cudaDeviceProp.
As of CUDA 4.1 & CUDA 5.0, the
cudaDeviceProp
structure contains the necessary information and
most of the information in
cudaDeviceProp
is self explanatory and commonly used CUDA device properties.
Query with
cudaGetDeviceProperpties() is useful for applications in which kernel
needs close interaction with the CPU, and applications that may be executed on the
integrated GPU that shares system memory with the CPU.
For example, if application depends upon on having double-precision floatin-point support,
then there is a need to check on each card that have compute capability 1.3 or higher
support double-precision floating point mathematical calculations. To run the application,
we need to find at least one device of compute capability 1.3 or higher.
First, we need to fill a
cudaDeviceProp strcuture with the properties related to device and
pass it to
cudaChooseDevice() to have CUDA runtime find a device that
satisfies the given constraint. The call to
cudaChooseDevice() returns a device ID that we can then
pass to
cudaSetDevice() . The description of program is as follows:
|
Hot to find Device
|
#include <stdio.h>
#include <time.h>
#include <cuda.h>
/* Utility Macro : CUDA SAFE CALL */
void
CUDA_SAFE_CALL( cudaError_t call)
{
cudaError_t ret = call;
switch(ret)
{
case cudaSuccess:
break;
default :
{
printf(" ERROR at line :%i.%d' ' %s\n",
__LINE__,ret,cudaGetErrorString(ret));
exit(-1);
break;
}
}
}
int main ( void ) {
int count;
int dev;
cudaDeviceProp prop;
CUDA_SAFE_CALL(cudaGetDeviceCount( &count) );
for(int i = 0; i < count; i++) {
CUDA_SAFE_CALL( cudaGetDeviceProperties( &prop, i) );
CUDA_SAFE_CALL( cudaGetDevice(&dev) );
printf("Information about the device \t: %d\n", count);
printf("Name \t\t\t\t: %s\n",prop.name);
printf("printf("ID of the device : %d\n", dev),
memset(&prop, 0, sizeof (cudaDeviceProp));
prop.major = 1;
prop.minor = 3;
CUDA_SAFE_CALL( cudaChooseDevice(&dev, &prop ) );
printf("ID of CUDA device closest to revision 1.3 :
%d \n", dev);
CUDA_SAFE_CALL( cudaSetDevice(dev) );
}
return 0;
}
|
|
CUDA Program for Vector Vector Addition
|
|
The input vectors are generated on host-CPU and transfer the vectors to device-GPU for vector
vector vector addition.
A simple kernel based on the grid of
thread blocks is generated in which thread is given a unique thread ID within its block.
Each thread performs partial addition of two vectors and the
final resultant value is generated on device-GPU and transferred
to host-CPU. Important steps are given below.
|
|
Steps
|
Description
|
|
1.
|
Memory allocation on host-CPU and device-GPU :
Allocate memory for two input vectors and resultant vector on
host-CPU & device-GPU
Use
cudaMalloc(void** array, int size)
|
|
2.
|
Input data Generation :
Fill the input vector with single/double precision real values using
randomized data as per input specification
|
|
3.
|
Transfer data from host-CPU to device-GPU:
Transfer the host-CPU vector to device-GPU to perform computation
Use
cudaMemcpy((void*)device_array, (void*)host_array, size , cudaMemcpyHostToDevice )
|
|
4.
|
Launch Kernel :
Define the dimensions for Grid and Block on host-CPU and launch the kernel for execution
on device-GPU.
Computation on device is performed for vector vector addition
|
|
5.
|
Transfer the result from device-GPU to host-CPU :
Copy resultant vector to host-CPU from device-GPU.
Use
cudaMemcpy((void*)host_array, (void*)device_array, size , cudaMemcpyDeviceToHost)
|
|
6.
|
Check correctness of the result on host-CPU
Compute vector-vector addition on host-CPU and Compare CPU & GPU results.
|
|
7.
|
Free the memory
Free the memory of arrays allocated on host-CPU & device-GPU
Use
cudaFree(void* array)
|
|
Example Program : Vector Vector Addition
|
|
#include <stdio.h>
#include <cuda.h>
#define N = 100
_global_void add (
int *a,
int *b,
int *c
) {
int tid = blockIdx.x;
// Start the data at this index
// CUDA C allows you to define a group of blocks in two dimensions
If ( tid < N)
c[tid] = a[tid] + b[tid];
}
/* Utility Macro : CUDA SAFE CALL */
void
CUDA_SAFE_CALL( cudaError_t call)
{
cudaError_t ret = call;
switch(ret)
{
case cudaSuccess:
break;
default :
{
printf(" ERROR at line :%i.%d' ' %s\n",
__LINE__,ret,cudaGetErrorString(ret));
exit(-1);
break;
}
}
}
int main ( void ) {
int a[N],b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// Allocate memory on the Device GPU
CUDA_SAFE_CALL( cudaMalloc( (void**)&dev_a, N * sizeof
(int) ) );
CUDA_SAFE_CALL( cudaMalloc( (void**)&dev_b, N * sizeof
(int) ) );
CUDA_SAFE_CALL( cudaMalloc( (void**)&dev_c, N * sizeof
(int) ) );
//fill Arrays 'a' and 'b' on the Device GPU
for(int i = 0; i < N; i++) {
a[i] = -i;
b[i] = i+1;
}
// Copy the Arrays 'a' and 'b' to Device GPU
CUDA_SAFE_CALL(cudaMemcpy(
&dev_a,
a,
N *
sizeof
(int),
cudaMemcpyHostToDevice) );
CUDA_SAFE_CALL(cudaMemcpy(
&dev_b,
b,
N *
sizeof
(int),
cudaMemcpyHostToDevice) );
add <<< N,1 >>>(dev_a, dev_b, dev_c);
CUDA_SAFE_CALL(cudaMemcpy(
&dev_c,
c,
N *
sizeof
(int),
cudaMemcpyDeviceToHost) );
// Display the results on Host CPU
for(int i = 0; i < N; i++) {
printf("%d + %d = %d \n", a[i], b[i], c[i] );
}
// Free the memory allocated on the Device GPU
cudaFree( dev_a);
cudaFree( dev_b);
cudaFree( dev_c);
return 0;
}
|
|
Vector Vector Addition (Thread Cooperation-Splitting Blocks)
|
|
In the earlier examples, a simple kernel add is based on the grid of
thread blocks is generated in which thread is given a unique thread ID within its block.
Each thread performs partial addition of two vectors and the
final resultant value is generated on device-GPU and transferred to host-CPU.
|
|
// N stands for number of Blocks
// 1 stands for number of threads per block
kernel <<< N,1 >>>();
|
|
The CUDA runtime allows these blocks to the split into threads. In earlier example,
N blocks are running on the GPU. To identify, which block is running, the variable
blockIdx.x is used in the kernel code.
|
|
_global_void add (
int *a,
int *b,
int *c
) {
int tid = blockIdx.x;
// Start the data at this index
// UDA C : Allows to define a group of blocks in two dimensions
If ( tid < N)
c[tid] = a[tid] + b[tid];
}
|
|
Here, the variable blockIdx.x is built in variable
that the CUDA runtime defines it. CUDA C defines a group of blocks in two dimensions.
CUDA runtime allows these blocks to be split into threads.
In above, the first argument in the angle brackets i.e., N represents the number of blocks to
be launched and the second parameter represents the number of threads per block. CUDA runtime
creates “N Parallel threads” in the above example as given below.
N blocks X 1 thread/block = N Parallel threads
In above example, a launch of N blocks of one thread is done at CUDA runtime.
|
|
|
|
In above, a launch of N threads , all within one block is
performed.
In earlier example program, the input and the output data is indexed by block Index, i.e.,
int tid = blockIdx.x;
We have a single block with many threads, to index the data by thread index, we have
int tid = threadIdx.x;
With above, we can re-write the code in order to move from a parallel block implementation
to a parallel thread implementation. The source code listing is given in the following
few lines.
|
|
_global_void add (
int *a,
int *b,
int *c
) {
int tid = threadIdx.x;
// Start the data at this thread index
// CUDA C : Allows to define a group of blocks in two dimensions
If ( tid < N)
c[tid] = a[tid] + b[tid];
}
|
|
The number of blocks in a single launch is 65,535 and the hardware limits the number of
threads per block with which we can launch a kernel.
maxThreadsPerBlock specifies the maximum and the number
can not exceed this as given in device properties structure. For many GPUs, this limit is 512 threads
per block.
To incorporate multiple blocks and threads, the indexing will start to look similar to the
standard method for converting from a two-dimensional index space to a linear space.
We use new built variable blockDim. This variable is a constant
for all blocks and stores the number of threads along each dimension of the block. In the
present example, we are using one-dimensional block, we refer only to
blockDim . The number of blocks along each dimension of the
entire grid are stored in gridDim. It is important to note that
gridDim, whereas a blockDim
is actually three-dimensional.
CUDA runtime allows you to launch a two-dimensional grid of blocks where each block is a three
dimensional array of threads.
|
|
_global_void add (
int *a,
int *b,
int *c
) {
int tid = threadIdx.x + bllockIdx.x + BlockDim.x;
}
|
|
Vector Vector Addition (Dimension of Grid & Each Block)
|
|
In CUDA, all the threads in a grid execute the same kernel function. Also, each thread
has unique coordinate to distinguish themselves from other and to identify the
approricate portion of the data to access. These threads are organized into a
two-level hierarchy using unique co-ordinates. These are blockIdx (for block index)
and threadIdx (for thread index)- assigned to them by the CUDA runtime system and these
variables can be accessed within kernel functions. When a thread executes the
kernel function, references to the blockIdx and threadIdx variable return the
coordinates of the thread. Additional built-in variables,
gridDim and BlockDim ,
provide the dimension of the grid and the dimension of each block respectively.
In CUDA thread organization, the
grid
consists of N thread blocks, and each block,
in turn, consists of M threads. Each grid has a total of N*M threads.
All blocks at the grid level are organized as a one- or two- dimensional (1D or 2D)
arrays; all threads within each block are also organized as a one- or two- or three-
dimensional (1D or 2D or 3D ) arrays.
In general, a grid is organized as a 2D array of blocks. Each block is organized into
a 3D array of threads. The exact organization of a grid is determined by the
execution configuration provided at kernel launch. The first parameter of the
execution configuration specifies the dimensions of the grid in terms of number
of blocks. The second specifies the dimensions of each block in terms of number
of threads. Each such parameter is a dim3 type, which is essentially a C struct
with three unsigned integer fields: x, y, and z. Because grids are 2D arrays of
block dimensions, the third field of the
grid
dimension parameter is ignored;
it should be set to 1 for clarity. The following host code can be used to launch
the kernel and details are explained below.
|
|
dim3 dimGrid(128, 1,1);
dim3 dimBlock(32, 1,1);
Kernel Functi on<<< dimGrid, dimBlock>>> (...);
// N stands for number of Blocks
// 1 stands for number of threads per block
kernel <<< N,1 >>>();
|
|
The first two statements initialize the execution configuration parameters.
Because the grid and the blocks are ID arrays, only the first dimension of
dimBlock and dimGrid are used. The other dimensions are set to 1. The third
statement is the actual kernel launch. The execution configuration parameters
are between <<< and >>>.
The values of grid Dim.x and
grid Dim.y can be calculated based on other variables at
kernel launch time. Once a kernel is launched, its dimensions cannot change.
All threads in a block share the same blockIdx value. The b1ockIdx.x value
ranges between 0 and gridDim.x-1 , and
the blockIdx.y value between 0 and
gridDim.y-1 .
In general, blocks are organized into 3D arrays of threads. All blocks in a grid
have the same dimensions. Each threadldx consists of three components: the x
coordinate threadldx.x, the y coordinate
threadldx.y,
threadldx.y, and the z coordinate threadldx.z
The number of threads in each dimension of a block is specified by
the second execution configuration parameter given at the kernel launch.
With the kernel, this configuration parameter can be accessed as a predefined
struct variable,
blockDim. The total size of a block is limited to 512 threads,
with flexibility in distributing these elements into the three dimensions as
long as the total number of threads does not exceed 512.
For example, (512, 1, 1), (8, 16, 2), and (16, 16, 2) are all allowable
blockDim values,
|
|
#include <stdio.h>
#include <cuda.h>
#define EPS 1.0e-12
#define GRIDSIZE 10
#define BLOCKSIZE 16
#define SIZE 128
double *dMatA,
*dMatB,
*dresult;
double *hMatA,
*hMatB,
*hMatC,
*hresult;
double *CPU_Result;
int velenth,
count = 0;
int blockWidth;
*hresult;
cudaEvent_t start, stop;
cudaDevelopProp start, stop;
int device_Count, size = SIZE;
_global_void vectvectadd(double dm1,
double *dm2,
double *dres,
int num) {
int int tx = blockIdx.x*blockDim.x + threadIdx.x;
int int ty = blockIdx.y*blockDim.y + threadIdx.y;
int int tindex = tx + (gridDim.x)*(blockDim.x)*ty;
if(tindex < num)
dres[tindex]= dm1[tindex]+dm2[tindex];
}
/* Check for safe return of all calls to the device */
/* Utility Macro : CUDA SAFE CALL */
void
CUDA_SAFE_CALL( cudaError_t call)
{
cudaError_t ret = call;
switch(ret)
{
case cudaSuccess:
break;
default :
{
printf(" ERROR at line :%i.%d' ' %s\n",
__LINE__,ret,cudaGetErrorString(ret));
exit(-1);
break;
}
}
}
/* Fill in the vector with double precision Values */
void
fill_dp_vector( double* vec,
int size)
{
//fill Arrays 'vector' on the Device GPU
for(int i = 0; i < size; ind++)
vec[i] = drand48();
}
/* Terminate and exit on errors on host-memory allocation.
This is called from the functions whch actually execute the benchmark */
void
check_block_grid_dim(
cudaDeviceProp devProp,
dim3 blockDim,
dim3 gridDim)
{
If
(blockDim.x >= devProp.maxThreadsDim[0] ||
blockDim.y >= devProp.maxThreadsDim[1] ||
blockDim.z >= devProp.maxThreadsDim[2] )
{
exit(-1);
}
If
(gridDim.x >= devProp.maxGridSize[0] ||
gridDim.y >= devProp.maxGridSize[1] ||
gridDim.z >= devProp.maxThreadsDim[2] )
{
exit(-1);
}
}
/* Memory Allocation Errors */
void
mem_error( char *arrayname,
char*benchmark,
intlen,
char*type
)
{
printf("\n Memory not sufficient to allocate for array
%s\n\t Benchmark : %s \n \t
Memory requested = %d number of %s elements\n",
arrayname, benchmark, len, type);
printf("\n\t Aborting \n\n");
exit(-);
}
/* Memory Allocation Errors */
int get_DeviceCount()
{
int count;
cudaGetDeviceCount(&count);
retun count;
}
/* Device Query Information */
void deviceQuery()
{
int device_Count, device;
device_Count = get_DeviceCount();
cudaSetDevice(0);
cudaGetDevice(&device);
cudaGetDeviceProerties(&deviceProp, device);
}
/* Launch Kernel */
void launch_kernel()
{
dim3 dimBlock(BLOCKSIZE, BLOCKSIZE);
dim3 dimGrid((vlength/BLOCKSIZE*BLOCKSIZE)+1,1);
check_block_grid_dim
(deviceProp,dimBlock,dimGrid);
vectvectadd <<< dimGrid, dimBlock >>>
(dMatA, dMatB, dresult, vlength);
}
/* Device Memory free */
void dfree (double* arr[ ], int len)
{
//Memory Free on Device GPU
for(int i = 0; i < len; i++)
CUDA_SAFE_CALL( cudaFree(arr[i]));
printf("memory freed \n ");
/* Vector Vector Addition */
void
vectvect_add_in_cpu(double *A, double *B, docuble *C, int size)
{
//Memory Free on Device GPU
for(int i = 0; i < size; i++)
c[i] = a[i] + b[i];
}
/* print_Gflops_rating */
void
print_Gflops_rating(float Tsec, int size)
{
//Measuring Gflop Rating
double gflops;
gflops = (1.0e-9 * ( (1.0 * size ) /Tsec) );
// printf("Gflops is \t%f\n",gflops);
}
/* print_on_screen */
void
print_on_screen(char *program_name, float tsec, double gflops,
int size, int flag)
// flag = 1 if Glfops calculation else flag = 0
{
printf("\n ........................ \n" program_name);
printf("\t SIZE \t TIME_SEC \t Gflops\n");
if(flag==1)
printf("\t%d \t%f \t%lf \t",size,tsec,gflops);
else
printf("\t%d \t%lf \t%lf \t",size,"---","---");
}
int main ( void ) {
double *array[3];
array[0] = dMatA;
array[1] = dMatB;
array[2] = dresult;
deviceQuery();
// CUDA Event : Time Calculation
CUDA_SAFE_CALL( cudaEventCreate(&start));
CUDA_SAFE_CALL( cudaEventCreate(&stop));
// Allocation host memory
hMatA = (double*) malloc( vlength * sizeof(double));
if(hMatA == NULL)
mem_error("hMatA","vectvectadd",vlength,"double");
hMatB = (double*) malloc( vlength * sizeof(double));
if(hMatB == NULL)
mem_error("hMatB","vectvectadd",vlength,"double");
hMatC = (double*) malloc( vlength * sizeof(double));
if(hMatC == NULL)
mem_error("hMatC","vectvectadd",vlength,"double");
// Allocation Device memory
CUDA_SAFE_CALL( cudaMalloc( (void**)&dMatA, vlenght * sizeof
(double) ) );
CUDA_SAFE_CALL( cudaMalloc( (void**)&dMatB, vlenght * sizeof
(double) ) );
CUDA_SAFE_CALL( cudaMalloc( (void**)&dresult,
vlenght * sizeof
(double) ) );
// Fill the data in Host Vectors
fill_dp_vector(hMatA,vlength);
fill_dp_vector(hMatB,vlength);
CUDA_SAFE_CALL(cudaMemcpy(
(void*)&dMatA,
(void*)&hMatA,
vlength *
sizeof (double),
cudaMemcpyHostToDevice) );
CUDA_SAFE_CALL(cudaMemcpy(
(void*)&dMatB,
(void*)&hMatB,
vlength *
sizeof (double),
cudaMemcpyHostToDevice) );
// CUDA Event : Time Calculation
CUDA_SAFE_CALL( cudaEventRecord (start, 0));
launch_kernel();
CUDA_SAFE_CALL( cudaEventCreate(&stop));
/* calling device kernel */
CUDA_SAFE_CALL(cudaMemcpy(
(void*)hresult,
(void*)dresult,
vlength *
sizeof (double),
cudaMemcpyDevicetoHost) );
printf("\n --------------------------------------------------");
// Calcultation of Gflops ↦ Printing
print_Gflops_rating(Tsec, vlenght);
print_on_scerren("vect vect Addition",
Tsec,print_Gflops_rating(Tsec,vlength),size,1);
// Free the memory allocated on the Device GPU
dfree(array,3);
// Free the memory allocated on the CPU
free(hMatA);
free(hMatB);
free(hresult);
return 0;
}
|
|
CUDA Compilation, Linking and Execution of Program
|
For Compilation of CUDA program, additional steps are involved, partly because the program targets
two different processor architectures (the GPU and a host CPU), and partly because of CUDA\92s hardware
abstraction. Compiling a CUDA program is not as straightforward as running a C compiler to convert
source code into executable object code. The same source file mixes C/C++ code written for both the
GPU and the CPU, and special extensions and declarations identify the GPU code. The first step
is to separate the source code for each target architecture.
nvcc is a compiler driver that simplifies the process of compiling CUDA code: It
provides simple and familiar command line options and executes them by invoking
the collection of tools that implement the different compilation stages.
nvcc\92s basic work flow consists in separating device code from host code and
compiling the device code into a binary form or cubin object. The generated host
code is output either as C code that is left to be compiled using another tool or as
object code directly by invoking the host compiler during the last compilation stage.
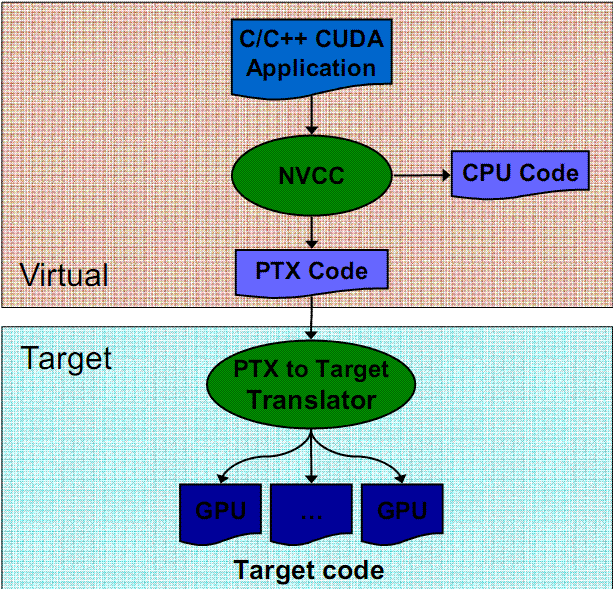
Figure 1. CUDA : Source Code Compilation Stages.
CUDA code should include the cuda.h header file. On the compilation
command line, the cuda library should be specified to the linker on UNIX
and Linux environments. Two steps are explained below.
Using command line arguments to compile CUDA source code:
The compilation and execution details of a CUDA program is simple as like compilation of C language source code.
$ nvcc -o < executable name > < name of source file >
For example to compile a simple Hello World program user can give :
$ nvcc -o helloworld cuda-helloworld.cu
Executing a Program:
To execute a CUDA Program, give the name of the executable at command prompt.
$ . / < Name of the Executable >
For example, to execute a simple HelloWorld Program, user must type:
$ ./helloworld
The output must look similar to the following:
Hello World!
|
|
|
| |
