|
Prog. on Multi-Core Processors with Intel Xeon Phi : Clik Plus
|
|
Intel Cilk Plus extends Cilk by adding array extensions, being incorporated in a
commercial compiler (from Intel), and having compatibility with existing debuggers.
The Cilk Plus language extends C++ to simplify writing parallel applications that efficiently exploit Intel Xeon Phi Coprocessors.
Example programs using
compiler pragmas, directives, function calls, and environment variables, Compilation and execution
of Cilk Plus programs, programs numerical and non-numerical computations
are discussed.
Compilation :
Cilk Plus and Vectorization / Not to Vectorization
Execution :
Set up Run time Prog. Env.
Execution
Cilk Plus Script
Offload Information :
Compiler Offload Pragma & Report
Compiler Offload Clauses
Cilk Plus :
Background
Overview
Using Cilk Plus Natively
Offloading Clik Plus
Matrix - Computation Codes
Example 1 : Vector-Vector Addition using Cilk Plus Framework
Example 2 : Vector-Vector Multiplication using Cilk Plus Framework
Example 3 : Matrix - Matrix Multiply using Cilk Plus Framework
Example 4 : Pie Computation - Cilk Plus Framework
Example 5 : Pie Computation - Cilk Plus Framework Implicit Offloading
Example 6 : Pie Computation - Simultaneous comp. on
Host & Accelerator using Cilk Plus
Example 7 : Poisson Solver using Cilk Plus Framework
References :
Xeon Phi Coprocessor
|
|
|
|
|
The key specifications of Intel Xeon Coprocessor
|
| Specification |
Feature |
| Clock Frequency |
1.091 GHz |
| No. of Cores |
61 |
| Memory Size / Type |
8 GB/GDDR5 |
| Memory Speed |
5.5 GT/sec |
| Peak DP/SP |
1.065/2.130 teraFLOP/s |
| Peak Memory Bandwdith |
352 GB/s |
|
|
|
|
|
|
Compilation of Sequential Programs : Compiler to Vectorize / NoVectorize
|
|
Using command line arguments (Vectorization & No Vectorization )
The compilation and execution of a program for an Intel Many Integrated Core (MIC)
architecture coprocessor (-mmic)
also known as Intel Xeon Phi Coprocessor are given below.
Compilation :
To compile the program : Using Intel C Compiler with Vectorization
# icpc -mmic -vec -report=3 -O3 <program name> -O
<Name of executable>
For example to compile a simple seq-matrix-matrix-multiply.c program user can type on the command line
# icpc -mmic -vec -report=3 -O3 <seq-matrix-matrix-multiply.c > -O
<seq-matrix-matrix-multiply>
To compile the program : Using Intel C Compiler without Vectorization
User can ask the complier not to vectorze the code with
-no -vec option and execute the code. It is possible to get less
performance.
# icpc -mmic -no-vec -vec -report=3 -O3 <seq-matrix-matrix-multiply.c > -O
<seq-matrix-matrix-multiply>
To compile the program using Makefile Utility, Using Intel C Compiler with Vectorization
make
Note: If the Makefile has
some extension like Makefile_C
then user is required to type
make -f Makefile_C
(instead of simply typing make)
make -f Makefile.OFFLOAD
(Compile using OFFLOAD mode)
make -f Makefile.NATIVE
(Compile using NATIVE mode)
make -f Makefile.OFFLOAD clean
(Clean the Object files & Binaries )
|
|
Intel compiler flag -cilk-serialize for the Intel Cilk Plus
implementation can be used for sequential execution.
The details ofr syntax of the command to compile the program on Intel Xeon Phi are given in the
following table.
|
|
|
|
|
Cilk Plus Set Up Run time Prog. Env.
|
|
|
|
|
|
|
|
|
Execution of Programs : Sequential & Clik Plus
|
|
To execute the applicaiton on coprocessor : Log-in to Xeon-Phi Coprocessor
To execute the program on coprocessor, the user Log-in to the
coprocessor, then simply type the name of executable
on command line.
./< Name of executable>
For example to execute a simple
seq-matrix-matrix-multiply.c application, user
types the command
./seq-matrix-matrix-multiply
For example to execute a simple
cilk-plus-matrix-matrix-multiply.c Cilk Plus application, user types
./cilk-plus-matrix-matrix-multiply
The expected output:
Initializing the Vectors
Computation startd
gigaFLOPs = ****
Time = ****
gigaFLOPs per Sec = *****
|
|
|
|
|
|
|
Execution - Script
|
|
Script to run on Xeon Phi in Native Mode :
export LD_LIBRARY_PATH=/opt/intel/mic/lib64/:/opt/intel/lib/mic:/opt/intel/mkl/lib/mic/:${LD_LIBRARY_PATH}
./run size number of worker
unset LD_LIBRARY_PATH
|
|
|
|
|
|
|
Compiler Offload Pragma & Report
|
Details of Code : Intel compiler's offload pragmas :
On Xeon-host, the code to transfer the data to the Xeon Phi coprocessor is automatically
created by the Intel complier. When the code is written using OpenMP pragmas to C/CC+ Fortran
code, the Intel complier encounters an offload pragma, it generates code for both the coprocessor
and the host.
The programmer responsibility is to include appropriate offload pragmas by adding data clauses.
Details can be found under "Offload Using a Pragma" in the Intel compiler documentation as
given in the references.
-
Using #pragma offload taret(mic) :
In this example, how to offload the matrix computation to the Intel Xeon Phi
coprocessor using #pragma offload target(mic)
is shown
-
Choose the target MIC out of Multiple Coprocessors :
The user could also specify the Intel Xeon-Phi Coprocessor
Number_Id in a system with multiple coprocessors (Ex. PARAM YUVA
Compute Nodes ) by using
#pragma offload target(mic:Number_Id).
|
Other Information about Intel compiler's offload :
-
Use -no-offload :
Offloading is enabled per default for the Intel compiler. Use
-no-offload to
disable the generation of offload code.
-
Vec Report :
Using the compiler option -vec-report2 one can see which loops have been vectorized
on the host and the MIC coprocessor:
-
Printing Data transfer (OFFLOAD_REPORT) :
By setting the environment variable OFFLOAD_REPORT
one can obtain information about
performance and
data transfers at runtime:
hypack-01: ~offload_c>
export OFFLOAD_REPORT=2
|
|
|
|
|
|
|
Intel Xeon Phi Coprocessor Compiler Offload Clauses
|
|
The Intel Xeon-Phi coprocessor programming environment provides " offload pragma" which
provides additional annotation so the compiler can correctly move data to and from
the external Xeon Phi Card. Note that single or multiple OpenMP loops can be contained
within the scope of the offload directive. The clauses are interpreted as follows:
Offload: The offload pragma keyword specifies different clauses that contain
information relevant to offloading to the target device.
target(mic:MIC_DEV)
is the target clause that tells the compiler to generate code for both the host
processor and the specified offload device i.e., Xeon Phi Coprocessor.
The constant parameter MIC_DEV is an an integer associated with Xeon-Phi device.
Note that the offload performs different operations as per requirement.
-
The offload runtime will schedule offload work within a single application in
a round-robin fashion, which can be useful to share the workload amongst
multiple devices.
-
The offload runtime will utilize the host processor when no coprocessors are present
and no device number is specified (for example, target(mic)).
-
programmers can use _Offload_to to specify a device in their code.
-
It is the responsibility of the programmer to ensure that any persistent
data resides on all the devices.
During the round-robin scheduling, the persistent data resides on all the devices
is important from performance point of view and to avoid PCIe bottlenecks. In general,
only use persistent data when the device number is specified.
-
Choose the target MIC out of Multiple Coprocessors :
The user could also specify the Intel Xeon-Phi Coprocessor
MIC_DEV in a system with multiple coprocessors (Ex. PARAM YUVA
Compute Nodes ) by using
#pragma offload target(mic:MIC_DEV).
in(Matrix_A:length(size*size)):
The in(var-list modifiersopt) clause explicitly copies
data from the host to the coprocessor. Note that:
-
The length(element-count-expr) specifies the number of elements to be transferred. The compiler will perform the conversion to bytes based on the type of the elements.
-
By default, memory will be allocated on the device and deallocated on exiting the scope of the directive.
-
The
alloc_if(condition) and
free_if(condition) modifiers can change the default behavior.
out(Matrix_A:length(size*size)):
The in(var-list modifiersopt) clause explicitly clause explicitly copies data from the coprocessor to the host. Note that:
-
The length(element-count-expr) specifies the number of elements
to be transferred. The compiler will perform the conversion to bytes based on the type of the elements. By default, memory will be deallocated on exiting the scope of the directive.
-
The
free_if(condition) modifier can change the default behavior.
|
|
|
|
|
|
|
|
|
|
|
|
|
Tuning & Performancre : Memory Alignment for Vectorizatio
|
-
Memory Alignment for Vectorization :
The matrices size is dynamically allocated using posix_memalign(), and their sizes
must be specified via the length() clause. Using in, out and inout one can specify
which data has to be copied in on Intel Xeon-Phi Coprocessor from host.
-
Data alignment - 64-Byte : It is recommended that for Intel Xeon Phi data is 64-byte (512 Bits) aligned as
given in the MIC architecture.
-
Alignment using #pragma vector alignment :
For proper alignment of data to get performance using Intel compiler vectorization,
#pragma vector aligned is used. This tells the compiler that all array data accessed
in the loop is properly aligned.
-
In addition, the -std=c99 directive command-line option tells the compiler to allow use
of the restrict keyword and C99 VLAs. Note that C99 restrict keyword that specifies that
the vectors do not overlap. (Compile with -std=c99 is required for efficient vectorization)
-
For SSE, the data is aligned to 32 Bytes (256 Bits) for AVX and 16 Bytes (128 Bits) for
SSE and for MIC architecture, data should be aligned to 64 Bytes (512 Bits) for the
MIC architecture.
|
|
|
|
|
|
|
Clik Plus : Introduction & Background
|
-
The Cilk language has been developed since 1994 at the MIT Laboratory for
Computer Science. It
is based on ANSI C, with the addition of just a handful of
Cilk-specific keywords.
Cilk is a faithful extension of C
The Cilk started as a runtime technology for algorithmic
multi-threaded programming developed at MIT and
MIT licensed Cilk technology to Cilk Arts, Inc. of
Lexington, MA. Later transitioned to Intel where former
Cilk Art developers added the technology to
the Intel compilers.
A commercial version of Cilk, called Cilk++ , that supported C++ and was
compatible
with both GCC and Microsoft C++ compilers, was developed by Cilk Arts, Inc.
-
The Cilk
keyword morphed into extern “Cilk”. Cilk++ introduced the notion of hyperobjects.
Its basic approach is that a programmer should
concentrate on structuring programs to expose parallelism and exploit locality while leaving a
run-time system to be responsible for scheduling computations to run efficiently on a given
multi-core processors.
-
The Cilk ++ language is particularly well suited for divide and conquer
algorithm having independent computations and works on problems involve work scheduling of
chunks of computations. The Clik ++ strategy is to break the problem into sub-problems (tasks) that can
be solved independently, then combining the results.
The tasks may be implemented in separate functions or in iterations of a loop.
Intel Cilk Plus extends Cilk by adding array extensions, being incorporated in a
commercial compiler (from Intel), and having compatibility with existing debuggers.
The Cilk Plus language extends C++ to simplify writing parallel applications that efficiently exploit Intel Xeon Phi Coprocessors.
The implementation of Intel Cilk Plus language extensions to GCC requires patches to the C and C++ front-ends, plus a copy of the Intel Cilk Plus runtime library ( Cilk Plus RTL ). Intel's set of C and C++ constructs for task-parallel and data-parallel programming are
designed to improve performance on multicore and vector processors.
Intel Threading Building Blocks ( TBB ) is a powerful solution for C++ programmers to address tasking in general, and a number of
related C++ issues like thread-aware memory allocation, thread safe versions of key STL con-tainer classes, portable locks and atomics, and timing solutions.
Cilk Plus can use components of
TBB include the scalable memory allocator and tick_count timing facility.
Some portions of TBB concepts can be used.
|
|
|
|
|
|
|
Clik Plus : Overview
|
|
Intel Cilk Plus adds simple language extensions to
express data and task parallelism to the C and C++
language implemented by the Intel C++ Compiler, which is
part of Intel Studio XE product suites and Intel Composer
XE product bundles.
-
Cilk Plus works on C and C++ programming, and provides support of good performance on scheduler perfor-mance and stack space, and has features to assist with vectorization (use of SIMD instructions). For data parallel applications, Cilk Plus provides strong
guarantees on scheduler performance
and stackspace, vector loops, array notations, elemental functions.
-
The Cilk Plus runtime system takes care of details like load balancing, synchronization, and communication protocols. Unique to Cilk, the runtime system guarantees efficient and predictable performance
and also guarantees bounds on stack size.
Cilk Plus has Simple, powerful expression of task parallelism
features. According to Intel, the three Intel Cilk Plus keywords provide a "simple yet surprisingly powerful" model for parallel programming, while runtime and template libraries offer a well-tuned environment for building parallel applications. The three Intel Cilk Plus keywords are:
_Cilk_spawn ;
_Cilk_sync ;
_Cilk_for ;
-
_Clk_spawn : Specify the start of parallel
execution. Specifies that a function call can execute asynchronously, without requiring the caller to wait for it to return. This is an expression of an opportunity for parallelism, not a command that mandates parallelism. The Intel Cilk Plus runtime will choose whether to run the function in parallel with its caller.
_Cilk_spawn - Annotates a function-call and indicates that execution may (but is not required to) continue without waiting for the function to return. The syntax is:
[<type>
<retval>=] _Cilk_spawn <postfix_expression>
(<expression-list> (optional))
-
_Cilk_sync : Specify the end of parallel execution.
Specifies that all spawned calls in a function must complete before execution continues. There is an implied cilk_sync at the end of every function that contains a cilk_spawn .
_Cilk_sync - Indicates that all the statements in the current Cilk block must finish executing before any statements after the _Cilk_sync begin executing. The syntax is:
_Cilk_sync ;
-
_Cilk_for : Parallelize for loops. (Allows iterations of the loop body to be executed in
_Cilk_for - is a variant of a for statement where any or all iterations may (but are not required to) execute in parallel. You can optionally precede _Cilk_for with a grainsize-pragma to specify the number of serial iterations desired for each chunk of the parallel loop. If there is no grainsize pragma or if the grainsize evaluates to '0', then the runtime will pick a grainsize using its own internal heuristics. The syntax:
[ #pragma cilk grainsize = ] _Cilk_for ( ; ; )
-
Hyper Objects (Reducers) :
Data parallelism for whole arrays or sections of
arrays and operations thereon. (Reducers provide a lock-free mechanism that allows parallel code to use private "views" of a variable which are merged at the next sync)
-
Array Notation :
Data parallelism for whole arrays or sections of
arrays and operations thereon. ( Intel Cilk Plus includes a set of notations that allow users to express high-level operations on entire arrays or sections of arrays. These notations help the compiler to effectively vectorize the application. Intel Cilk Plus allows C/C++ operations to be applied to multiple array elements in parallel, and also provides a set of builtin functions that can be used to perform vectorized shifts, rotates, and reductions )
-
Elemental Functions : Enables data parallelism of whole functions or
operations which can then be applied to whole or
parts of arrays. ( An elemental function is a regular function which can be invoked either on scalar arguments or on array elements in parallel. They are most useful when combined with array notation or #pragma simd. )
#pragma simd : This pragma gives the compiler permission to vectorize a loop even in cases where auto-vectorization might fail. It is the simplest way to manually apply vectorization.
Along with these keywords, you can use #pragma SIMD directives to communicate loop information to the vectorizer so it can generate better vectorized code. The five #pragma SIMD directives are: vectorlength, private, linear, reduction, and assert. The list below summarizes the five directives. For a detailed explanation please refer to the " Intel Cilk Plus Language Specification" at
http://www.cilkplus.org
1. #pragma simd vectorlength (n1, n2 ...):
Specify a choice vector width that the back-end may use to vectorize the loop.
2. #pragma SIMD private (var1, var2, ...):
Specify a set of variables for which each loop iteration is independent of each other iterations.
3. #pragma SIMD linear (var1:stride1, var2:stride2, ...): Specify a set of variables that increase monotonically in each iteration of the loop.
4. #pragma SIMD reduction (operator: var1, var2...): Specify a set of variables whose value is computed by vector reduction using the specified operator.
5. #pragma SIMD assert: Directs the compiler to halt if the vectorizer is unable to vectorize the loop.
Intel Cilk Plus involves the compiler in optimizing and
managing parallelism. Integration with the compiler infrastructure allows
many existing compiler optimizations to apply to the
parallel code. The compiler understands these four
parts of Intel Cilk Plus as given above and is therefore able to help
with compile time diagnostics, optimizations and
runtime error checking.
-
Intel Cilk Plus, where the array notation allows
the compiler to vectorize, that is, utilize Intel Streaming SIMD
Extensions (Intel SSE) to maximize data -parallel performance,
while adding the cilk_for causes the driver function of the simulation to be parallelized, maximizing use of the multiple processor cores for task-level parallelism.
-
Intel Cilk Plus to give you
both parallelization of the main driver loop using cilk_for,
and the array notation for the simulation kernel to allow
vectorization.
Array notation provides a way to operate on slices of
arrays using a syntax the compiler understands and
subsequently optimizes, vectorizes, and in some cases
parallelizes. This is the basic syntax:
[< lower bound > : < length > : < stride >]
where the <lower bound >, <length >, and
<stride > are
optional, and have integer types. The array declarations
themselves are unchanged from C and C++ array-definition
syntax.
-
SIMD Vectorization and Elemental Functions are a part of Intel Cilk
Plus feature supported by the Intel C++ Compiler that
provide ways to vectorize loops and user defined functions. The Intel Compilers provide unique capabilities to enable
vectorization. The programmer may be able to help the compiler to vectorize more loops through a simple programming style
and by the use of compiler features designed to assist vectorization.
-
The Intel compiler was able to auto-vectorize the loops in the original application
after we have added the #pragma ivdep directive before each loop. Note that the
functions inside the loops use transcendental operations. The Intel compiler uses the
Short Vector Math Library (SVML) library to vectorize in this case. As an alternative to
#pragma ivdep directive, we can use the Intel Cilk Plus Array Notation for
replacing the loops, which gives a very clear way to express loop vectorization
Task Parallelism :
Task parallelism can be achived by using the
keywords _Cilk_spawn and _Cilk_sync.
To parallelize the application , the Cilk_spawn will
take care of the task creation and scheduling of tasks to
threads for you, while the _Cilk_sync indicates the end of
the parallel region at which point the tasks complete and
serial execution resumes.
In typical serial computations, the the two calls to
taret subroutine between the _Cilk_spawn and
_Cilk_sync can
be executed in parallel, depending on the
resources available to the Intel Cilk Plus runtime.
The cilk_stub.h header file will essentially comment
out the keywords so that other compilers will
compile the files without any further source code
changes.
The cilk_stub.h header file will essentially comment
out the keywords so that other compilers will
compile the files without any further source code
changes.
-
Parallelism in a C or C++ application can be simply implemented using the
Intel Cilk Plus keywords, reducer hyper-objects, array
notation and elemental functions. It allows you to take full advantage of
both the SIMD vector capabilities of your processor
and the multiple cores, while reducing the effort needed to develop
and maintain your parallel code.
-
Intel Cilk Plus, via the _Cilk_for keyword which replaces the for keyword.
This solution is defined as fine-grained parallelism. Since it requires explicitly for
loops, it cannot use the vector syntax based on Intel Cilk Plus Array Notation. The
arrays of data and results are shared among the threads, so that there is a negligible
increment in the memory footprint of the application when running in parallel.
Furthermore, race conditions can easily be avoided since the parallel regions are
confined to the loop iterations. Also the loop that computes the reduction has been
parallelized.
-
Intel Cilk Plus provides a special template class (cilk::reducer_opadd<>) for
the reduction that also works with custom types and gives reproducibility results.
Consequently, the Intel Cilk Plus implementation becomes easier than in OpenMP.
-
The Intel Cilk Plus implementation based on
_Cilk_ for keyword cannot be accommodated for the coarse-grained parallelism.
Therefore, we have implemented a new algorithm based on _Cilk_spawn and
_Cilk_sync keywords. The algorithm splits the events in blocks, each block being
executed in parallel by a _Cilk_spawn call.
-
The Cilk Plus implementation can be classifed as fine-grained parallelism with
vectorization based on #pragma ivdep and block splitting and
Corase-grain parallelism with block splitting, vectorization based either on
#pragma ivdep or Intel Cilk Plus Array Notation and dynamic scheduling of the blocks.
-
All Cilk Plus these implementations can be executed with MPI with a single
executable with some command line parameter options for setting the
implementation and block size for matrix computation codes.
|
|
|
|
|
|
|
Using Cilk Plus Natively
|
|
TBB parallel programming model codes run natively on the Intel Xeon Phi coprocessor
and can scale upto larger number of threads.
In order to initialize your compiler environment
variables needed to set up TBB correctly, typically the
/opt/intel/composerxe/tbb/bin/tbbvars.csh
or
tbbvars.sh
script with intel64 as the argument is
called by the
/opt/intel/composerxe/bin/compilervars.csh
or
compilervars.sh
script with
intel64 as argument. (e.g. source /opt/intel/composerxe/bin/compilervars.sh intel64)
A minimal C++ TBB example looks as follows:
#include "tbb/task_scheduler_init.h"
#include "tbb/parallel_for.h"
#include "tbb/blocked_range.h"
using namespace tbb;
int main() {
task_scheduler_init init;
return 0;
}
The using directive imports
the namespace tbb
where all of the library's classes and functions are found. The
namespace is explicit in the
first mention of a component, but implicit afterwards. So with the
using namespace
statement present you can use the library component identifiers without having to write out
the namespace
prefix tbb before each of them.
The task scheduler is initialized by instantiating a
task_scheduler_init object in the main function.
The definition for the
task_scheduler_init class is included from the corresponding header
file. Actually any thread using one of the provided TBB template algorithms must have such an
initialized
task_scheduler_init object. The default constructor for the
task_scheduler_init object informs
the task scheduler that the thread is participating in task execution, and the destructor informs
the scheduler that
the thread no longer needs the scheduler.
With the newer versions of Intel TBB as used in a MIC environment the
task scheduler is automatically initialized, so there is no need to explicitely initialize it
In the simplest form scalable parallelism can be achieved by parallelizing a loop of iterations
that can each run
independently from each other.
The parallel_for template
function replaces a serial loop where it is safe to process each element
concurrently.
The template function
tbb::parallel_for
breaks the iteration space into chunks, and runs each chunk on a separate thread.
The first parameter of template function call
parallel_for is a
blocked_range object that describes the entire iteration
space
from 0 to n-1. The
parallel_for divides the iteration space into subspaces for each of the
over 200 hard-ware threads.
blocked_range<T> is a template class provided by the TBB library describing a
one-dimensional T.
The
parallel_for class works just as well with other kinds
of iteration spaces. The library provides
blocked_range2d for two-dimensional spaces.
There exists also the possibility to define own spaces. The general constructor of the
blocked_range template class is
blocked_range(begin,end,grainsize) . The
T.
specifies the value type. begin represents the
lower bound of the half-open range interval [begin,end) representing the iteration space.
end represents the
excluded upper bound of this range. The grainsize is the approximate number of elements
per sub-range. The default grainsize is 1.
A parallel loop construct introduces overhead cost for every chunk of work that it schedules.
The MIC adapted
Intel TBB library chooses chunk sizes automatically, depending upon load balancing needs.
The heuristic normally works well with the default grainsize. It attempts to limit overhead
cost while still
providing ample
opportunities for load balancing. For most use cases automatic chunking is the recommended choice.
There might
be situations though where controlling the chunk size more precisely might yield better performance.
|
|
|
|
|
|
|
Offloading Cilk Plus
|
|
The Intel TBB header files are not available on the Intel MIC target environment by default
(the same is also
true for Intel Cilk Plus). To make them available on the coprocessor the header files have to
be wrapped with #pragma offload directives as demonstrated in the example below:
#pragma offload_attribute (push,target(mic))
#include " tbb/task_scheduler_init.h "
#include " tbb/parallel_for.h "
#include " tbb/blocked_range.h "
#pragma offload_attribute (pop)
Functions called from within the offloaded construct and global data required on the Intel
Xeon Phi coprocessor
should be appended by the special function attribute
__attribute__((target(mic))) .
Codes using Intel TBB with an offload should be compiled with -tbbflag
instead of -ltbb
On the coprocessor you can then export the library path and run the application.
|
|
|
|
|
EXample Programs on Vector Vector Addition and Multiplication
|
|
EXample Programs on Matrix Matrix Multiplication
|
|
Example. 3
Matrix - Matrix Multiply on Xeon Host using Cilk Plus framework
(Download source code :
matrix-matrix-multiply-clik-plus-native.cpp
matrix-matrix-multiply-clik-plus-offload.cpp
Makefile_clik_plus.NATIVE
Makefile_clik_plus.OFFLOAD
execute_clik_plus_offload.sh;
execute_clik_plus_native.sh )
Objective
Input
Description
Output
Summary
|
|
Objective
Extract performance in G/flops for Matrix Matrix Multiply
and analyze the performance on Intel Xeon based on OpenMP.
Description
Two input matrices are filled with real data and matrix-matrix Multiply is performed
using compiler & vectorization features.
It is assumed that both matrices are of same size. This example demonstrates the use of
Cilk Plus Programming features to obtain the maximum achievable performance.
The key computation of the code is two inner loops & an outer loop i.e.,
|
// Zero the Matrix_C matrix
for (int i = 0; i < size; ++i)
for (int j = 0; j < size; ++j)
Matrix_C[i][j] = 0.f;
// Compute matrix multiplication.
for (int i = 0; i < size; ++i)
for (int k = 0; k < size; ++k)
for (int j = 0; j < size; ++j)
Matrix_C[i][j] += Matrix_A[i][k] * Matrix_B[k][j];
}
}
|
|
|
In implementation, every thread will work its own row array section of input Matrix_A and multiply with
each column of Matrix_B, resulting to give an output array of resulting matrix Matrix_C. It is
assumed that the size of the two input square matrices is divisible by number of threads.
For convenience sake, we use one core and 2 or 4 four Cilk Plus threads for Matrix-Matrix
Multiply algorithm.
|
|
Input
Number of threads , Size of the Matrices.
Output
Prints the time taken for the computation and G/flops and the number of threads.
|
|
Example 4 :
Pie Computation on Xeon-Phi using Cilk Plus framework
Objective
Input
Description
Output
(Download source code :
pie-comp-cilk-plus-native.cpp;
pie-comp-cilk-plus-offload.cpp;
Makefile_cilk_plus.NATIVE ;
Makefile_cilk_plus.OFFLOAD )
env_var_setup_cilk_plus_NATIVE.sh;
env_var_setup_cilk_plus_offload.sh;
|
- Objective
Write a Cilk Plus program to compute the value of pi function by numerical integration of
a function f(x) = 4/(1+x 2 ) between the limits 0 and 1.
- Description
There are several approaches to parallelizing a serial program. One approach is
to partition the data among the processes. That is we partition the interval of
integration [0,1] among the processes, and each process estimates local integral over
its own subinterval. The local calculations produced by the individual
processes are combined to produce the final result. Each process sends its integral to process 0,
which adds them and prints the result.
To perform this integration numerically, divide the interval from 0 to 1 into n
subintervals and add up the areas of the rectangles as shown in the Figure 3 (n
= 5). Large values of n give more accurate approximations of pi.
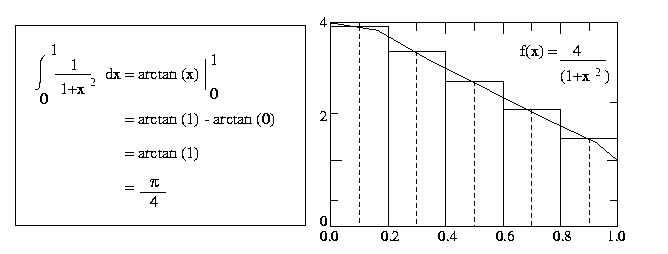
Figure Numerical integration of pie function
We assume that n is total number of subintervals, p is the number
of processes and p < n. One simple way to distribute the total
number of subintervals to each process is to dividen by p. There
are two kinds of mappings that balance the load. One is a block mapping,
partitions the array elements into blocks of consecutive entries and assigns
the block to the processes. The other mapping is a cyclic mapping. It
assigns the first element to the first process, the second element to the
second, and so on. If n > p, we get back to the first process,
and repeat the assignment process for remaining elements. This process is
repeated until all the elements are assigned. We have used a cyclic mapping
for partition of interval [0,1] onto p processes.
- Input
Number of threads, Number of Intervals
- Output
Prints the time taken for the computation of Pie Value and the number of threads.
|
|
|
|
|
Example. 5 :
Pie Computation on Xeon Host / Xeon Phi Coprocessor - Implicit offload
(Assignment)
-
Programmer marks variables that need to be shared between host
and card
- The same variable can then be used in both host and coprocessor code
- Runtime automatically maintains coherence at the beginning and end
of offload statements
- Syntax: keyword extensions based
- Example: _Cilk_shared double Pie_Comp
Heterogeneous Compiler Offload using Implicit Copies
Section of memory maintained at the same virtual address on
both the host and Intel MIC Architecture coprocessor
Reserving same address range on both devices allows
-
Seamless sharing of complex pointer-containing data structures
-
Elimination of user marshaling and data management
-
Use of simple language extensions to C/C++
Heterogeneous Compiler Offload using Implicit Copies
When shared memory is synchronized
-
Seamless sharing of complex pointer-containing data structures
-
Automatically done around offloads (so memory is only synchronized on
entry to, or exit from, an offload call)
-
Only modified data is transferred between CPU and coprocessor
-
Dynamic memory you wish to share must be allocated with special
functions:
_Offload_shared_malloc,
_Offload_shared_aligned_malloc, _Offload_shared_free,
_Offload_shared_aligned_free
|
|
|
|
|
Example. 6 :
Pie Computation Simultaneous computation on
Host and Accelerator - Cilk Plus
(Assignment)
_Cilk_shared double myworkload(double input){
// do something useful here
return result;
}
int main() {
result1 = _Cilk_spawn _Cilk_offload myworkload(input2);
result2 = myworkload(input1);
cilk_sync;
}
-
Function is generated for both MIC and CPU
-
One thread is spawned and executes the offload code on MIC
-
The host executes the same function and waits
|
|
|
|
|
Example 7 :
Poisson Equation Solver on Xeon-Phi using Cilk Plus framework
(Assignment)
|
| |
|
|
