|
hyPACK-2013 : Prog. on HPC GPU Cluster : OpenMP & OpenCL Prog.
|
|
A prototype Hybrid Adaptive Cluster that can be made "adaptive" to the application it is running, assigning
the most effective resources in real-time as per application demands, without requiring modifications to the
application. The goal of this mixed environment is to provide total workflow optimization, which takes
cares-off applications
that do not parallelize well on scalar processors, can be optimized with the appropriate
computation model. The system aim is
to develop system software and integrate components of the State-of-the-Art-Technology such as
Reconfigurable FPGA,
Stream accelerators NVIDIA GPU computing, AMD Stream computing and IBM Cell Broadband Engine
Processors, and Multi-Core Processors.
|
|
Example 1.1
|
Write a OpenMP-OpenCL program to compute vector vector multiplication
on Multi-CPU using global memory features of OpenCL. (OpenCL Events is
used to synchronize the CPU and GPU devices.)
|
Example 1.2
|
Write a OpenMP-OpenCL program to Compute the value of pie value by
Numerical Integration
using OpenMP directives and OpenCL ( Assignment )
|
Example 1.3
|
Write a OpenMP-OpenCL program to perform Matrix Vector multiplication
using BLAS1 Library. ( Assignment )
|
Example 1.4
|
Write a OpenMP-OpenCL program to perform Matrix Matrix multiplication
using BLAS1 library on device GPU
|
Example 1.5
|
Write a OpenMP-OpenCL program to perform Matrix Matrix multiplication
on Multi-GPUs using global memory & local memory
( Assignment )
|
|
|
Description of OpenMP - OpenCL Programs |
-
Objective
Write a OpenMP-OpenCL program to compute vector vector multiplication using global
memory model of OpenCL
-
Description
This is an openMP implementation on host-CPU using p threads of
OpenMP and computation on device-GPU.
This is an implementation of vector-Vector multiplication
using the block striped partitioning algorithm on host-CPU
and device-GPU.
Each OpenMP thread gets the block of entries of vector
and each transfers the block of its vector elements to the device-GPU from
host-CPU.
On each device-GPU,the partial elements of the two vectors
are multipled by calling the OpenCL kernel Vector-VectorMultiplication
and writes the partial sclar value. The result scalar is transfered
from device-GPU to host-CPU.
-
Output
OpenMP Master thread on host-cpu prints the resultant sclar value n.
|
|
Example 1.2:
|
Write a OpenMP-OpenCL program to Compute the value of pie value by Numerical Integration
using OpenMP directives and OpenCL. ( Assignment )
|
-
Objective
Write a OpenMP-OpenCL program to Compute the value of pie value by
Numerical Integration
using OpenMP directives and OpenCL
-
Description
This is an openMP implementation on host-CPU using p threads of
OpenMP and computation on device-GPU using OpencL APIs
One approach is to partition the data among the processes. That is we partition the interval of
integration [0,1] among the OpenMP threads, and each thread estimates local integral over
its number of subinterval on GPU using OpenCL APIs. The comptuations on GPU produced
by the individual
OpenMP thread are transformed back to host-CPU . These results
are combined on host-CPU to produce the final result. On host-CPU,
prints the result.
To perform this integration numerically, divide the interval from 0 to 1 into n
subintervals and add up the areas of the rectangles as shown in the Figure 1 (n
= 5). Large values of n give more accurate approximations of pi
. Use MPI point-to-point communication library calls.
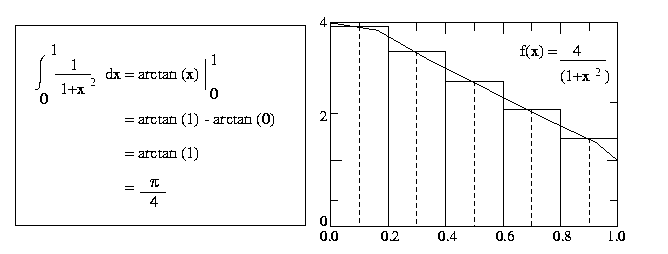
Figure 1 Numerical integration of pie function
We assume that n is total number of subintervals, p is the number
of processes and p < n. One simple way to distribute the total
number of subintervals to each process is to dividen by p. There
are two kinds of mappings that balance the load. One is a block mapping,
partitions the array elements into blocks of consecutive entries and assigns
the block to the processes. The other mapping is a cyclic mapping. It
assigns the first element to the first process, the second element to the
second, and so on. If n > p, we get back to the first process,
and repeat the assignment process for remaining elements. This process is
repeated until all the elements are assigned. We have used a cyclic mapping
for partition of interval [0,1] onto p processes.
-
Input
OpenMP master thread on Host-CPU prints the computed value of pi function.
-
Output
OpenMP master thread on Host-CPU prints the resultant vector
|
|
Example 1.3:
|
Write a OpenMP-OpenCL program to perform Matrix vector multiplication based on OpenMP & CUDA
directives and use OpenCL BLASlibrary funcation calls to compute
block vector into vector multiplication. ( Assignment )
|
-
Objective
Write a OpenMP-OpenCL program to Matrix vector multiplication based on
CUBLAS1 library funcation calls to compute
vector vector multiplication
-
Description
This is an openMP implementation on host-CPU using p threads of
OpenMP and computation on device-GPU.
This is an implementation of Matrix-Vector multiplication
using the block striped partitioning algorithm on host-CPU
and device-GPU.
Each OpenMP thread gets the block of rows of the matrix
and each transfers the block of its rows and vector to the device-GPU from
host-CPU.
Then each device-GPU multiplies the corresponding block matrix with the
vector by calling the OpenCL kernel VectorVectorMultiplication (BLAS1 library call)
and writes the partial product into the result vector. The result vector is transfered
from device-GPU to host-CPU.
on host-CPU to the output array.
-
Input
OpenMP Master thread on host-cpu reads the input matrix and the vector of size n .
-
Output
OpenMP master thread on Host-CPU prints the resultant vector
|
clOmpMatMatMultShared.c / matrixMultShared.cl
-
Objective
Write a OpenMP OpenCL program to compute Matrix Matrix multiplication based on
OpenMP & OpenCL directives and use BLAS1 library funcation calls to compute
vector vector multiplication
-
Description
This is an openMP implementation Matrix-Matrix multiplication on host-CPU using p threads of
OpenMP and computation on device-GPU in which
block striped partitioning of the both input matrices on host-CPU
is performance and on device-GPU, the CUDA BLAS1 library call is used to
compute vector-vector multiplication algorithm.
Each OpenMP thread gets the block of rows of the input matrix A and a block of
columns of input matrix B. Computations of block matrices are performed
on device-GPU using tuned BLAS1 mathematical libraries on device-GPU.
Then, one device-GPU multiplies the corresponding block matrices by calling
the OpenCL kernel
MatrixMatrixMultiplication using BLAS1 library
and writes the partial output matrix i.e., C . The result block matrix
C is transfered
from device-GPU to host-CPU.
-
Input
OpenMP Master thread on host-cpu reads the both input matrices of square size n
-
Output
OpenMP master thread on Host-CPU prints the resultant output matrix
|
|
Example 1.5:
|
Write a OpenMP-OpenCL program to perform Matrix Matrix multiplication using global
and local memory.
|
-
Objective
Write a OpenMP OpenCL program to compute Matrix Matrix multiplication based on
OpenMP & OpenCL directives using global and local memory
-
Description
This is an openMP implementation Matrix-Matrix multiplication on host-CPU using p threads of
OpenMP and computation on device-GPU in which
block striped partitioning of the both input matrices on host-CPU
is performed and on device-GPU.
Each OpenMP thread gets the block of rows of the input matrix A and a block of
columns of input matrix B. Computations of block matrices are performed
on device-GPU on device-GPU.
Then, one device-GPU multiplies the corresponding block matrices by calling
the OpenCL kernel performs
MatrixMatrixMultiplication
and writes the partial output matrix i.e., C . The result block matrix
C is transfered
from device-GPU to host-CPU.
-
Input
OpenMP Master thread on host-cpu reads the both input matrices of square size n
-
Output
OpenMP master thread on Host-CPU prints the resultant output matrix
|
|
|
|
